Hey there! Let's talk about spam filters. You know, those annoying emails that keep showing up in your inbox, even though you never signed up for them. Yeah, those. Well, a spam filter is a program that filters out those unwanted emails and messages. Pretty cool, right?
So, we're going to build and evaluate a spam filter. We'll be using a dataset from the MIT website, which has two data fields: text of the email and a spam label (1 if spam, 0 otherwise). Once we create a data frame from the DocumentTermMatrix, we'll implement three different models: logistic regression, classification tree, and random forest.
#logistic regression model. this is going to overfit.
spamLog <- glm(spam ~ ., data = train, family = binomial())
#classification tree model
spamCART <- rpart(spam ~., data = train, method = 'class')
set.seed(123)
#random forest model
spamRF <- randomForest(spam ~ ., data = train)We then evaluate these models using the test data:
predict_log2 <- predict(spamLog, type = 'response', newdata = test)
predict_cart2 <- predict(spamCART, newdata = test)[, 2]
predict_rf2 <- predict(spamRF, type='prob', newdata = test)[, 2]We can evaluate the models even further by creating and iterating over new test datasets. And if you're interested in checking out the full script, it's available on GitHub.
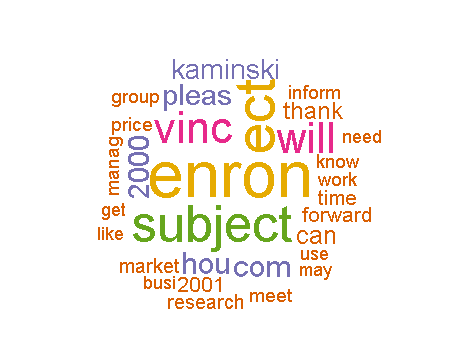
By the way, I've included some cool visualizations of the most appeared terms and focused terms for you to check out. Take a look at the most appeared terms in the first image. Pretty interesting, right? And in the second image, you'll see the focused terms that are important for identifying spam. And last but not least, the third image shows the 30 most appeared terms.


Thanks for reading, and I hope you learned a thing or two about spam filters!