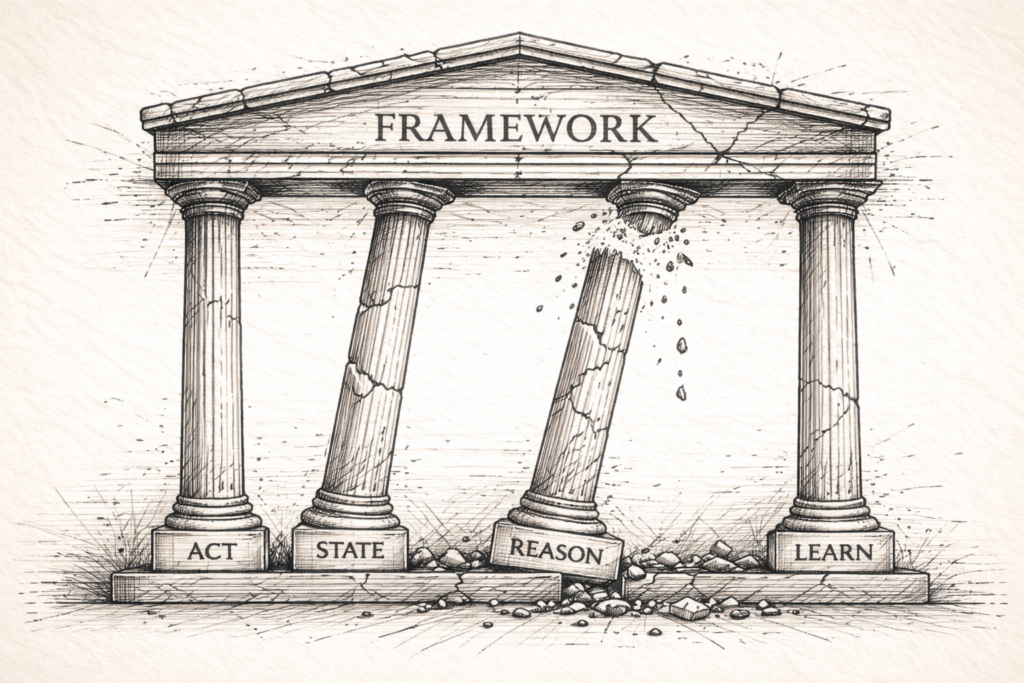
A systematic evaluation of LangChain's architectural foundations using the SRAL framework
Scorecard Summary
| Component | Score | Key Finding |
|---|---|---|
| State | ⚠️ Weak-to-Moderate | Memory is optional, not architectural. Context-window dependency remains default. |
| Reason | ⚠️ Moderate | ReAct built-in, but easy to build ungrounded chains—no enforced verification. |
| Act | ✅ Moderate-to-Strong | Excellent tool library and error handling. Feedback loops exist but aren't enforced. |
| Learn | ❌ Absent | No learning mechanisms. Persistence ≠ learning. Each run independent. |
How to Read These Scores
| Score | Meaning |
|---|---|
| ✅ Strong | The component is architecturally enforced. The framework guides you toward correct usage by default. Doing it wrong requires deliberate effort. |
| ⚠️ Moderate | The component is supported but optional. Capabilities exist, but the framework permits—even makes easy—incorrect usage. Discipline required. |
| ⚠️ Weak | The component is an afterthought. Basic support exists, but defaults actively work against reliability. Significant architectural effort required to compensate. |
| ❌ Absent | The component doesn't exist in the framework. You must build it entirely yourself or accept the limitation. |
The key distinction: supported vs. enforced. A framework can support good architecture while permitting bad architecture. SRAL evaluates what the framework guarantees, not what it allows.
The Pattern Behind the Failures
Here's a pattern I've seen repeatedly.
A team builds a customer support agent with LangChain. It handles the first few messages beautifully—retrieves relevant docs, answers questions, escalates appropriately. The demo impresses everyone.
Then conversations drag on. By message fifteen, the agent contradicts itself. It recommends a product it already said was out of stock. It forgets the customer's original issue. The team debugs frantically. The chains look fine. The tool calls return correct data.
The problem isn't visible in any component.
Tracing backward: the agent's actions were correct given its reasoning. Its reasoning was coherent given its state. But its state was incomplete—the agent’s effective context had degraded: either the system hit context limits (hard failure) or earlier turns were trimmed/summarized (soft loss), and the agent still proceeded without a first-class pinned constraint model.
The visible failure was in reasoning. The root cause was in state.
This pattern persists even in teams that know better—because the framework's defaults don't guide them toward explicit state management. The pit of success leads elsewhere.
This is the blind spot. We assume the model is the bottleneck. We optimize prompts, add tools, try newer models. But reasoning quality is downstream of state quality. When context windows overflow, when memory is an afterthought, reasoning has nothing stable to reason about.
Reasoning depth cannot exceed state stability.
This isn't a model problem. It's an architecture problem. And LangChain—for all its capabilities—doesn't solve it for you.
Why This Evaluation
LangChain earned its dominance for good reasons. The composability model is genuinely elegant. The tool ecosystem is unmatched. For prototyping agents quickly, nothing else comes close.
But prototyping isn't production. And capability isn't architecture.
I developed SRAL (State-Reason-Act-Learn) as a framework for evaluating agent architectures by asking four questions in sequence: What does it remember? How does it decide? How does it affect the world? How does it improve? These questions reveal structural foundations that capability lists conceal. (Introduction to SRAL)
What follows is a systematic evaluation of LangChain against these four components. Not a tutorial. Not a takedown. An architectural assessment that reveals what the framework guarantees—and what it leaves to you.
A Note on Scope
This evaluation covers the LangChain ecosystem, including LangGraph. LangGraph's StateGraph and built-in checkpointing represent genuine architectural progress—state management is more explicit, persistence is better integrated. These improvements matter.
But the core pattern holds: these capabilities exist as options, not requirements. You can still build stateless chains. You can still ignore checkpointing. The framework enables good architecture. It doesn't enforce it.
The question isn't "can you build reliable agents with LangChain?" You can. The question is "does the framework guide you there by default?" It doesn't.
SRAL Evaluation
State: The Optional Foundation
LangChain historically treated durable state as an add-on. The framework provides memory modules (ConversationBufferMemory, ConversationSummaryMemory, VectorStoreMemory), but they’re optional. Newer LangChain/LangGraph patterns increasingly favor explicit message history and graph state with checkpointing, but the key point remains: it’s optional unless you design for it. LangChain lets you build stateless chains and agents by default; durable state is an explicit opt-in, not an architectural requirement.
This single sentence explains most production failures.
Most examples rely on conversation history in the context window. When that fills up, information disappears. LangChain offers management strategies—trim messages, summarize earlier content—but these are reactive mitigations, not architectural solutions. The agent doesn't know it's lost information. It proceeds with confidence built on absence.
State can be made robust. LangChain supports external persistence through checkpointers and cross-conversation memory via the Store API. LangGraph improves this further with explicit StateGraph definitions and typed state schemas. But these require deliberate architectural choices that developers must make themselves. The framework enables good architecture. It doesn't enforce it.
Strengths:
- Pluggable memory abstractions (buffer, summary, vector)
- External persistence via checkpointers and Store API
- LangGraph's
StateGraphprovides explicit state definitions - Context management tools for overflow handling
Weaknesses:
- Optional by default—most developers skip it
- Context truncation happens silently
- No architectural guarantee of state coherence
Score: ⚠️ Weak-to-Moderate
When state is optional, demos work and production fails. The gap is architectural.
You've seen this in teams. When nobody writes down why a decision was made, the same debates resurface six months later. The same mistakes get relitigated. Institutional knowledge walks out the door and nobody notices until it's gone.
Agents without explicit state are the same. They don't fail dramatically. They just... drift.
Memory isn't a feature. Memory is identity.
Reason: Guided but Not Grounded
LangChain handles reasoning well on the surface. The ReAct pattern—alternating reasoning steps with tool calls—is built-in. Dynamic prompts adjust based on context. Tool observations feed back into subsequent decisions.
But the framework doesn't enforce grounding.
LangChain's composability is powerful. You can chain operations elegantly, build complex flows with minimal code. That same flexibility permits reasoning flows that never verify assumptions against reality. You can build chains that skip ReAct entirely, constructing multi-step reasoning with no environmental feedback.
The Structured Output guide reveals the tension: when output fails validation, the model retries "with error details." That's grounded reasoning—error as feedback. But it only applies when validation is configured. The architecture permits grounding. It does not require it.
Strengths:
- ReAct implementation interleaves reasoning and acting
- Dynamic prompts generate context-aware system messages
- Tools can feed observations back to inform reasoning
Weaknesses:
- Grounding not enforced—can be bypassed
- Sequential chains without verification are permitted
- Quality depends entirely on developer discipline
Score: ⚠️ Moderate
There's a pattern here too. In distributed systems, we learned that optimistic assumptions compound into systemic failures. The same applies to agent reasoning. Each unverified step builds on the previous. Errors don't surface—they accumulate.
Ungrounded reasoning is optimistic concurrency for cognition. Eventually, it breaks.
Act: The Capability Layer
This is where LangChain excels.
The @tool decorator makes custom tools trivial. Built-in integrations cover web search, code interpreters, and Model Context Protocol for external servers. Error handling is comprehensive—middleware for retries, fallbacks, custom error processing. Tool results flow back as ToolMessage objects, and the ReAct pattern creates natural feedback cycles.
The primitives are production-grade. Parallel execution, streaming, integrations that can invoke provider-side tools (when the model supports them) and support streaming/parallel execution in the application runtime.. If you need action capabilities, LangChain delivers.
But—and this matters—these feedback loops are patterns in agents, not requirements across the framework. You can execute tools and ignore results. The framework permits it.
Strengths:
- Extensive tool ecosystem with easy custom creation
- Parallel calls, streaming, server-side execution
- Robust middleware for retries and fallbacks
Weaknesses:
- Feedback loops optional in chains
- Guardrails exist (retries, fallbacks, middleware), but they’re opt-in and not structurally enforced across chains/agents.
Score: ✅ Moderate-to-Strong
Powerful primitives in well-designed architectures produce reliable agents. The same primitives in poorly-designed architectures produce fragile ones. LangChain provides the primitives. What you build with them is on you.
Tools don't grant capability. They expose the architecture beneath.
Learn: The Missing Component
There isn't one.
Across agents, memory, tools, middleware, persistence, multi-agent systems—learning mechanisms are absent entirely.
LangChain provides persistence: checkpointers save state, the Store API enables cross-conversation memory. But persistence is not learning. Storing what happened is not the same as improving from experience.
The agent doesn't identify which strategies worked, which tools failed, or which reasoning patterns led to success. Each invocation is independent. Mistakes made in one conversation repeat in the next. Successful patterns vanish when the thread ends. The agent remains a perpetual novice—no matter how many conversations it handles.
Strengths:
- Persistence infrastructure exists
- Semantic search could theoretically support experience retrieval
Weaknesses:
- No learning mechanisms in any architectural layer
- No optimization from accumulated experience
- No transfer between sessions
Score: ❌ Absent
To be fair: this gap isn't unique to LangChain. No major agent framework has solved architectural learning. AutoGen, CrewAI, Semantic Kernel—none provide mechanisms for agents to improve from experience without human intervention or retraining. This is an industry-wide gap, not a LangChain-specific failure.
But an industry-wide gap is still a gap. The absence is understandable. It's also a limitation.
Human expertise comes from pattern recognition across experiences. An agent that cannot learn is condemned to rediscover what it already knew—forever.
Persistence is storage. Learning is improvement. LangChain provides the former, not the latter.
Predicted Failure Modes
Based on this evaluation, LangChain agents will fail in predictable patterns:
Context Overflow Collapse (State)
Long-horizon tasks degrade as context fills. Agents contradict earlier constraints, forget established facts. The failure is silent—the agent doesn't know what it's lost.
Hallucination Cascades (Reason)
Chains without verification build elaborate reasoning on unverified assumptions. Each layer compounds errors until the output is confidently wrong.
Perpetual Novice Syndrome (Learn)
Agents repeat the same mistakes indefinitely. No transfer between conversations, no improvement from feedback, no development of expertise.
Fragile Multi-Step Workflows (Combined)
Demos succeed because they're short and carefully constructed. Production fails because scale exposes what the architecture doesn't guarantee.
Recommendations
These gaps don't make LangChain unusable. They make architectural discipline essential.
For State: Use a production checkpointer (e.g., PostgresSaver) from day one to make thread state durable. Separately, use a store for long-term memories (prototype: InMemoryStore; production: a durable store) and keep critical constraints in a pinned, structured object outside the conversation buffer. Test with conversations that exceed your context limit before you ship.
For Reason: Wrap every chain in a verification step. Use RunnablePassthrough to inject state checks between reasoning stages. If your agent makes a claim, the next step should verify it against a tool call—not just proceed.
For Act: Implement ToolRetryMiddleware with exponential backoff. Don't just execute tools; validate results before passing them downstream. Make feedback loops explicit in your graph design.
For Learn: LangChain won't help here. Build it yourself: log every tool call and outcome to a vector store, tag successes and failures, retrieve relevant experiences at the start of each session. It's manual, but it's the only path to improvement.
The framework gives you capabilities. You must supply the architecture.
The Deeper Pattern
LangChain is a mirror.
It reflects the architectural discipline—or absence of it—that you bring to the problem. Powerful tools in careful hands build reliable systems. The same tools without architectural rigor produce systems that fail in production while working perfectly in demos.
This pattern is older than AI. Every powerful framework faces the same dynamic. Rails didn't guarantee good web applications. Kubernetes doesn't guarantee reliable infrastructure. LangChain doesn't guarantee reliable agents.
Capability without structure is fragile. This has always been true.
The demos work because they're short. Production fails because it's long. The difference isn't the framework. The difference is architecture.
The model is not the agent. The architecture is.
Resources
- SRAL Framework Paper: SRAL: A Framework for Evaluating Agentic AI Architectures
- Introduction to SRAL: The Four Questions I Ask About Every Agent