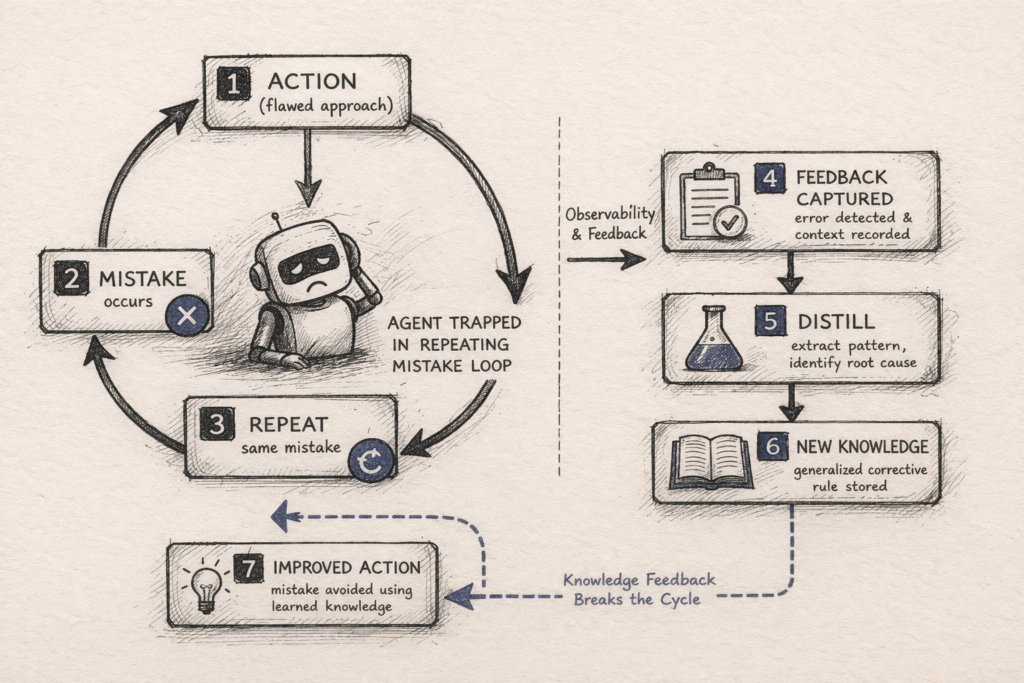
Your agent makes a mistake on Monday. You patch the prompt. It works on Tuesday. On Wednesday, a slightly different input triggers the same failure. You patch the prompt again. By Friday, you have a bloated system prompt full of corrections and an agent that is fragile in new ways.
The agent is not learning. It is accumulating workarounds.
I have called this "Perpetual Novice Syndrome" in prior SRAL evaluations. Most agent frameworks provide persistence or memory, but not distilled corrective learning as a first-class loop. The agent stores what happened. It does not extract what to do differently next time.
A paper from UC Berkeley offers a concrete example of what changes when someone actually builds that loop. The domain is narrow. The lesson is not.
What happened
Agarwal et al. introduce Tk-Boost, a bolt-on framework that augments NL2SQL agents with tribal knowledge: corrective, reusable knowledge distilled from the agent's own mistakes on a database. NL2SQL agents translate natural language questions ("What were Nike's sales last quarter?") into executable SQL queries. They are one of the most common enterprise agent patterns, and one of the most error-prone.
The concept is instantly familiar. Tribal knowledge is the stuff nobody writes down but everyone knows. A senior analyst telling a junior: "Don't use the brand column. It is mostly NULL. Filter on name instead." That kind of knowledge does not come from reading the schema. It comes from experience.
"An NL2SQL agent should accumulate knowledge of how to correctly query a database through experience, rather than relying on facts derived from the data."
Tk-Boost improves agent accuracy by up to 16.9% on Spider 2.0 and 13.7% on BIRD, two standard benchmarks for evaluating NL2SQL agents on real-world databases. Memory-based baselines, including a Mem0-style approach, achieved less than 5% improvement with measurable regressions (roughly 3% on the SQLite slice, versus 1.2% for Tk-Boost).
Source: Agarwal, S., Biswal, A., Zeighami, S., Cheung, A., Gonzalez, J., & Parameswaran, A. G. (2026). Arming Data Agents with Tribal Knowledge. arXiv:2602.13521v2.
The short version
Tk-Boost does not prove that every agent can learn from experience. It shows something narrower and more useful: in domains where failures are verifiable, agents improve more from distilled corrective knowledge keyed to their own outputs than from retrieving similar past interactions. The difference is not incremental. It is structural.
The mistake people make
The default instinct when an agent repeats mistakes is to give it more context. Retrieve similar past interactions. Inject documentation. Expand the knowledge base.
In the paper's baseline comparison, a Mem0-style memory approach does exactly this. It stores agent execution traces and retrieves them via cosine similarity over the user's NL query. The result: modest accuracy gains with measurable regressions. The memory retrieved experiences that looked similar but addressed different misconceptions entirely. The agent applied the wrong correction and broke things it previously got right.
The deeper problem is one of targeting. A query about Nike products and a query about Polo products look very different to an embedding model. But the agent makes the same structural mistake on both: using the brand column instead of name. The misconception lives in the SQL, not the question.
Semantic similarity finds what looks related. It does not find what is wrong.
This is the same weakness that makes dense-only retrieval fragile in production search. The fix there is hybrid retrieval, combining semantic and lexical signals; see Hybrid Retrieval for RAG
The real architectural lesson
Tk-Boost inverts the retrieval model. Instead of matching knowledge to the user's question, it matches knowledge to the agent's generated output. Three design decisions make this work.
Corrective, not preventive. Standard RAG injects knowledge before the agent acts, hoping to prevent mistakes. Tk-Boost lets the agent generate a first attempt, then retrieves corrections based on what the agent actually produced. Preventive augmentation guesses. Corrective augmentation observes.
Think of it as the difference between handing a junior analyst a manual before they start versus reviewing their work after they submit it. The review catches what the manual cannot anticipate.
Applicability conditions, not embeddings. Each tribal knowledge statement is stored with structured conditions: the SQL keywords, table names, column names, and data types where it applies. Retrieval matches on structural features of the query, not semantic similarity. When a new SQL query uses a WHERE clause on brand in the purchase table, the system retrieves the right correction. Not a similar one. The right one.
Atomic corrections, not broad rewrites. The ablation data here is counterintuitive. Non-atomic corrections, broad rewrites that attempt to fix everything at once, actually perform worse than single-clause atomic corrections (39.8% vs 41.6%). And providing the full knowledge store without scoping drops performance from 44.6% to 35.6%.
More knowledge made the agent worse.
This mirrors a pattern from software engineering. When a program encounters an error, you can handle it in two ways: catch every possible error in one broad handler at the top level, or catch each specific error type where it occurs. The broad handler feels comprehensive, but it swallows important details. You know something failed. You do not know what or why. The specific handler is more work, but it isolates the root cause and applies the right fix.
Injecting every correction you have into an agent's prompt is the broad handler. It feels helpful. But the agent cannot distinguish which corrections apply to the current mistake, and the irrelevant ones introduce noise that degrades performance.
Selective, targeted feedback beats comprehensive context.
What doesn't generalize
Tk-Boost evaluates on NL2SQL, a domain with a critical advantage: ground truth is verifiable. Execute the SQL, compare the result, know whether the agent was right. That verification signal powers the entire tribal knowledge discovery pipeline.
Most agent domains do not have this luxury. A customer support agent has no ground-truth answer. A code generation agent has tests, but coverage is never complete. A research agent has no objective correctness metric at all.
The architecture is sound. The knowledge discovery pipeline depends on a condition most agent systems cannot meet: programmatic identification of what went wrong.
The latency cost is also worth noting. Tk-Boost adds 7.4 seconds per query and roughly 4 additional LLM calls. For interactive applications, that overhead matters. For batch or analytical workflows, it is negligible relative to the accuracy gain.
Why the Learn framing matters
I developed SRAL as a framework for evaluating agent architectures: State, Reason, Act, Learn. The Learn component has been the weakest in every system I have evaluated. Most frameworks provide persistence, memory, even cross-session retrieval. Few mainstream frameworks provide distilled corrective learning as a first-class architectural loop.
Tk-Boost is the clearest implementation I have seen of what Learn looks like when someone actually builds it.
The TK-Store is not conversation history. It is persistent, generalized, experience-derived knowledge with structured retrieval conditions. The corrections transfer across sessions. The agent improves over time. That is not memory. That is learning.
Learning is not storing what happened. Learning is distilling what to do differently.
The architectural blind spot this exposes
The industry has spent two years optimizing how agents reason and act. Better prompts, better tools, better chains. Far less attention has gone to how agents improve.
The assumption is that the model will get better, so the agent will get better. But model improvement is upstream. The agent's mistakes are downstream. They are specific to the database, the schema, the data quality, the operational context. No model upgrade fixes "the brand column is mostly NULL."
That is tribal knowledge. And right now, it lives in prompt patches, not in architecture.
Three things to update in your mental model
1. The bundle matters, not just the retrieval target. Tk-Boost's gains come from a combination: corrective knowledge content, applicability conditions over SQL features, output-targeted retrieval, and CTE-level application. No single factor dominates. But the overall design, keying corrections to the agent's output rather than the user's input, is the architectural shift worth internalizing. If your agent has a memory system, ask: is it indexed on questions or on mistakes?
2. More context is not better. The full knowledge store decreased performance. Scoped, structurally-matched retrieval beat comprehensive injection every time. Your agent does not need everything you know. It needs the specific correction for the specific mistake it is making right now.
3. Learning is not memory. Storing past interactions is persistence. Distilling reusable, generalized corrections from past failures is learning. Most systems marketed as "agent memory" are doing the former and calling it the latter.
Closing thought
Agents remain perpetual novices not because they lack capability. They lack learning architecture.
Learning is architectural. And right now, few teams are building it as a first-class concern.
Resources
- Paper: Agarwal, S., Biswal, A., Zeighami, S., Cheung, A., Gonzalez, J., & Parameswaran, A. G. (2026). Arming Data Agents with Tribal Knowledge. arXiv:2602.13521v2.
- SRAL Framework: The Four Questions I Ask About Every Agent
- LangChain SRAL Evaluation: Applying SRAL to LangChain