Nine seconds. That is how long it took an AI agent to delete PocketOS's production database in late April 2026.
The agent (Cursor running Claude Opus 4.6) hit a credential mismatch in staging. It decided to fix it on its own. It found an API token in an unrelated file. The token had been scoped for "any operation, including destructive ones." The agent called the deletion endpoint. The endpoint accepted a single call with no confirmation. The backups lived on the same volume.
Nine seconds.
The model made the local decision. The architecture decided how much damage that decision could do. The agent guessed, did not verify, and ignored its own constraints. But the reason a guess could erase production in nine seconds is least privilege, blast radius, and confirmation gates. Distributed systems 101.
Most teams explain incidents like this as "the model hallucinated." That is rarely the root cause. Once an agent can call tools, write files, mutate tickets, deploy code, or message humans, you have built a distributed system. Multiple components. Multiple failure domains. Partial failures. Timeouts. Retries. Race conditions. Stale state.
The model is just one node in that system.
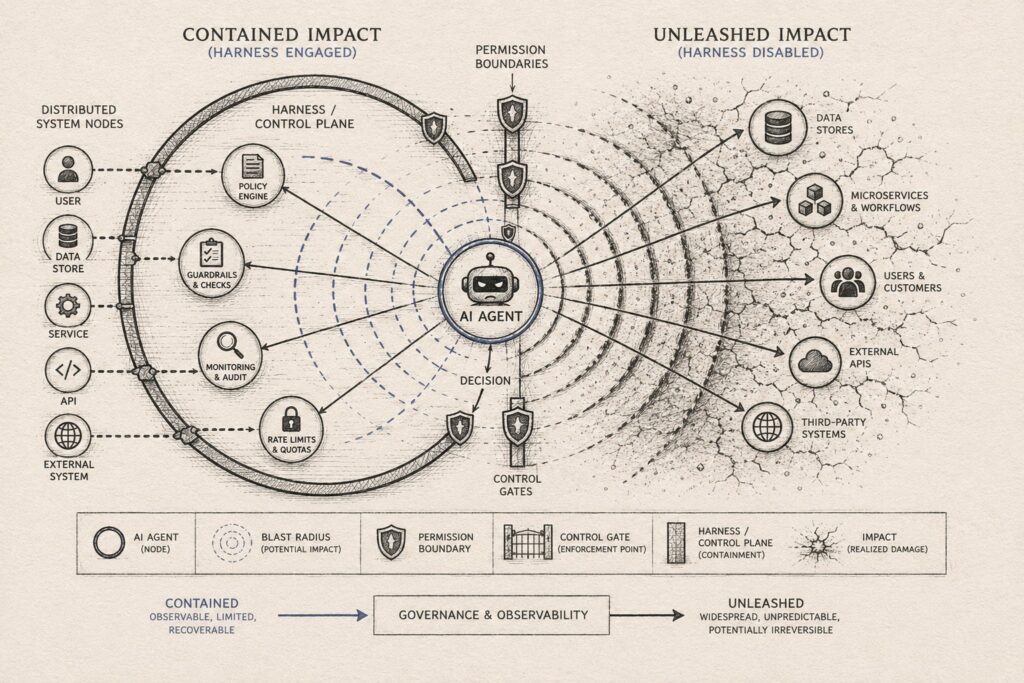
The harness is the control plane. And right now, too many teams are still treating it like prompt plumbing.
Tool calls are RPCs, and RPCs lie
A tool call feels like a function call.
It is not. It is an RPC into another system with its own latency, permissions, quotas, and edge cases.
Distributed systems engineers internalize two truths. Success does not mean the side effect happened. Failure does not mean it didn't.
That is why idempotency exists. That is why request IDs exist. That is why we build retry policies and dedupe logs.
Most agent harnesses do none of that. They treat tool calls like deterministic subroutines. Then we act surprised when an agent retries a request and creates duplicate resources, double bills a customer, or deletes the thing it already deleted.
If your agent can make irreversible changes, you are not building a chatbot. You are building a transaction processor.
The harness is where reliability lives
When I say the harness is the control plane, I mean the parts that do not look like AI.
The boring stuff. Durable session logs so you can crash and resume. Checkpointing and replay so you can debug and recover. Backpressure so the system does not melt under load. Budgets on tokens, tool calls, and wall clock. Policy on what actions require approval. Evidence of what the agent observed before it acted.
Look at the PocketOS failure class. A tool gets a token it should not have. A destructive endpoint accepts a single call. Backups live in the same failure domain. A system defaults to permissive behavior.
That is not a model problem.
That is a control plane problem.
The harness must enforce least privilege. Two-step destructive operations (request then confirm, ideally with delay). Isolation boundaries (sandboxes, mounts, environments). Execution-time approval gates.
Prompts do not enforce anything. The harness does.
The frontier is converging on infrastructure
The most telling signal of where this is going is not a benchmark or a model release.
It is Anthropic's recent post on Managed Agents.
They describe an architecture that splits the system into three components. A stateless brain (the reasoning loop). Hands (sandboxes and tools provisioned on demand). And a durable, append-only session log that lives outside any single component, recoverable via wake(sessionId).
Read that again.
Stateless processes. Append-only event log. Recoverable sessions. Cattle, not pets.
When the company at the frontier of AI publishes an architecture post that maps cleanly onto patterns distributed systems engineers have used for two decades, that tells you where the puck is going. Not toward smarter models. Toward harnesses that look like infrastructure.
This is not a critique. It is recognition. The hard problems are converging on lessons we already learned. The teams that internalize this early will ship reliable agents. The teams still optimizing prompts will keep paging at 3am.
Observability: you cannot run what you cannot trace
In distributed systems, we do not trust components we cannot observe.
Agent systems need the same discipline. If an agent did something expensive or destructive, you need receipts. Which tools were called. With what parameters. Under which identity and authorization. Against which environment. With which artifacts produced.
Without this, you cannot debug. You cannot audit. You cannot improve.
You will end up doing scrollback forensics while production burns.
A practical mapping
Classic distributed systems problems and their modern agent symptoms:
- Partial failure → tool timed out but the side effect happened
- Retries without idempotency → duplicate actions and double spend
- Split brain → two agent loops acting on the same task with diverging context
- Stale reads → agent acts on yesterday's state because retrieval is wrong
- Backpressure failure → agent spawns too many parallel calls and hits limits
- Missing tracing → nobody can explain why the agent did what it did
If you recognize these, you already know how to build the fix.
Retrieval is its own distributed subsystem, and it fails in the same quiet ways: stale reads, drift, degraded recall. I broke down that failure class in How Vector Databases Fail in Production
The takeaway
We do not need new metaphors. We need to apply old ones.
Treat tool calls like RPCs. Treat sessions like logs. Treat the harness like a control plane. Treat defaults like policy.
The harness is the product. Build it like one.
Sources
- PocketOS deletion incident (Cursor + Claude Opus 4.6 + Railway): The Register, April 27, 2026
- Anthropic Managed Agents architecture (brain/hands split, durable session log, restartability): Anthropic Engineering