Two services agree on bare JSON over HTTP, with no schema governing it. That is not a contract. That is a hope.
A bare JSON REST endpoint between two internal services is a handshake held together by documentation, convention, and the assumption that nobody renames a field on a Tuesday. The JSON body does carry shape: field names and a runtime structure the server can read. What it does not carry is an enforced contract. Nothing fails at build time when the shape drifts. The caller sends a body, the server parses it, and the only thing that enforces agreement is human discipline and a wiki page that is already out of date.
To be precise, this is an argument about a default, not about REST as a discipline. Schema and contract tooling for REST exists and works: OpenAPI specifications, JSON Schema, generated clients, and consumer-driven contracts can all give an HTTP boundary a real, checked contract. The problem this post is about is the untyped JSON-over-HTTP that most internal calls fall back to, where none of that tooling is wired in and the contract lives only in people's heads.
For services exposed to browsers and third parties, that looseness is a feature. REST is ubiquitous, debuggable with curl, and cacheable through the whole HTTP toolchain. Roy Fielding designed it for exactly that world: large-scale, evolvable, hypermedia-driven, with independent parties who cannot coordinate.
But most calls inside a microservice system are not that. They are one team's service calling another team's service, both deployed from the same organization, both changing on overlapping schedules. There, the looseness stops being a feature and becomes a liability.
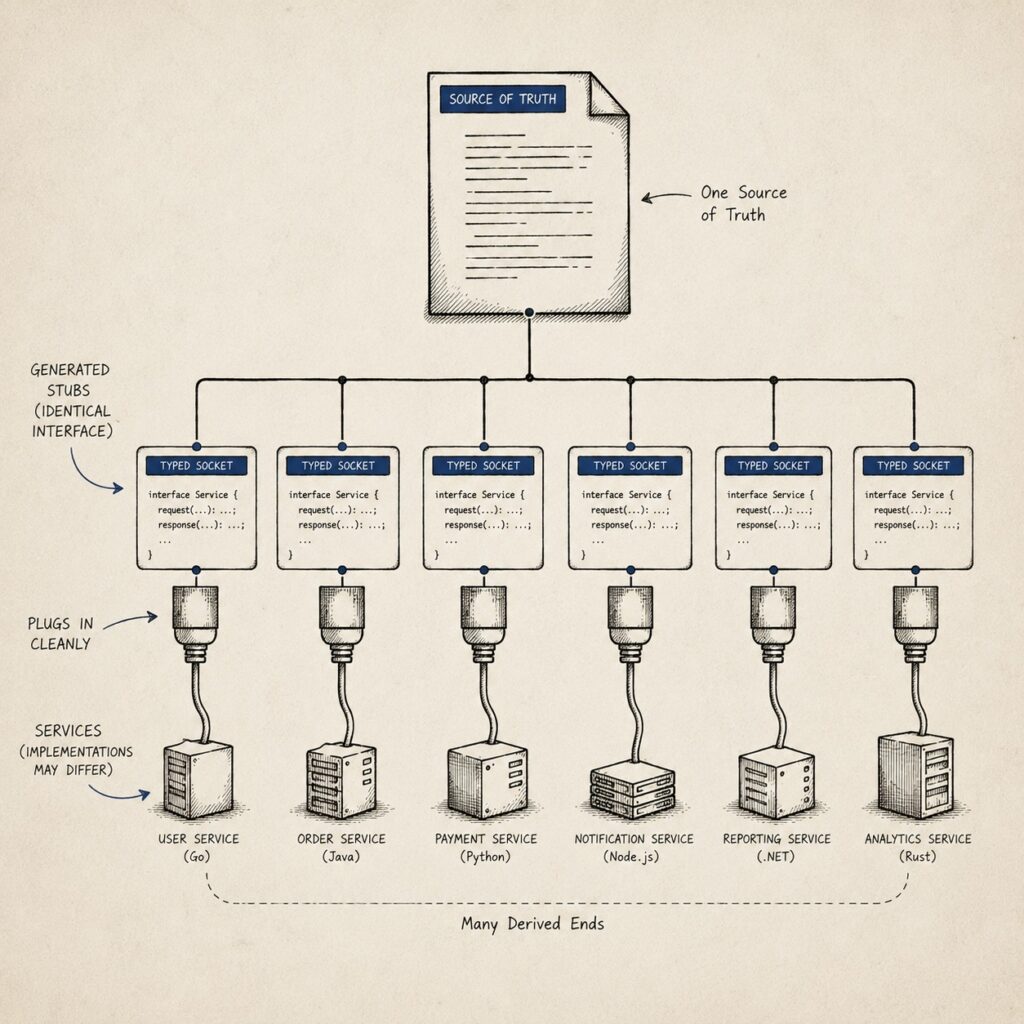
Inside the system, the schema should be the contract, and the contract should be a compiler error when you break it.
What untyped JSON does not give you between services
The cost of stringly-typed service boundaries is not visible on day one. It shows up later, in three predictable places.
The first is drift. The server adds a required field. The client does not know. The two now disagree, and nothing tells either of them until a request fails in production against real data. The contract existed only as a shared understanding, and shared understanding decays.
The second is the per-service translation tax. Every consumer hand-writes its own model of the payload, its own (de)serialization, its own validation. The same JSON shape gets re-implemented in three languages by three teams, each with subtly different assumptions about what null means and which fields are optional. The boundary is described N times and agreed on zero.
The third is what REST does not express cleanly as first-class call shapes. A request-response verb is a poor fit for a server pushing a stream of updates, or a client uploading a long sequence, or two services holding an open bidirectional channel. People bolt those onto HTTP with polling, long-polling, and one-off socket protocols, and each bolt-on is its own little undocumented contract.
None of these are arguments against HTTP, or against REST done with schema discipline. They are arguments against the common default: untyped JSON-over-HTTP, a format designed for uncoordinated public clients, used without governance for coordinated internal ones.
Contract-first inverts the dependency
The shift that gRPC and Protocol Buffers make is not mainly about speed, though binary framing over HTTP/2 is genuinely leaner than JSON over HTTP/1.1. The shift is about where the contract lives.
In a contract-first world, you write the interface before you write either side of it. A .proto file declares the service, its methods, and the exact shape of every message, in one language-neutral definition that both sides import. That file is not documentation of the contract. It is the contract.
From it, code generation produces typed client stubs and server interfaces in every language you target. The client does not hand-roll a model of the response. It calls a generated method that returns a generated type. The server does not parse a loose body. It implements a generated interface. Serialization, deserialization, and the wire format are no longer code anyone writes by hand. They are derived from the schema, the same way current state is derived from a log.
This is the same instinct as an interface definition language has always served, pulled to its conclusion: the definition is upstream of every implementation, and every implementation is downstream of it. Change the .proto, regenerate, and the type system in each service tells you, at compile time, exactly what no longer fits. The drift that untyped JSON surfaces as a 500 in production, gRPC surfaces as a build failure on the branch.
In the Akka world this is the line between Akka HTTP and Akka gRPC. Akka HTTP is the right tool for the public, REST-shaped edge. Akka gRPC takes the .proto and generates the typed, streaming service for the internal mesh, with the four call shapes, unary, server-streaming, client-streaming, and bidirectional, available as first-class methods rather than protocols you invent.
Streaming is a first-class verb, not a workaround
The streaming point deserves its own weight, because it is the capability REST never had a clean answer for.
HTTP/2 multiplexes many logical streams over one connection, and gRPC exposes that directly. A method can return a stream of messages instead of one. A client can send a stream. Both can stream at once over a single open channel. For the things that are actually streams, telemetry, progress, live updates, large transfers, the contract finally matches the shape of the data.
This is why the pattern lands so naturally in reactive systems. Back-pressured, asynchronous streams between services are the core idea, and a typed bidirectional channel is the transport that idea was waiting for. The message shape is still the .proto. The stream is just the verb.
The schema is the contract, so the schema needs governance
Typed contracts do not remove the hard problem of distributed systems. They relocate it. You no longer fight drift at runtime; you fight versioning at the schema.
And Protocol Buffers' versioning model has rules you have to internalize, because they are the difference between a safe change and an outage. Fields are identified by tag number, not by name. The wire format does not carry field names; it carries numbers. So a field's number is sacred. You can rename a field freely, because the name is only a label in the generated code. You can add a field, and old readers will simply ignore the tag they do not recognize. You can stop using a field. What you must never do is reuse a retired field's number for a different meaning, because some old message, somewhere, still carries the old value under that tag, and an old client still expects it.
A protobuf field number is a permanent decision. Treat reusing one the way you treat reusing a primary key.
Get this right and the format gives you real forward and backward compatibility: new servers read old messages, old servers read new ones, and you can deploy the two sides on independent schedules. That property, independent deployability across a version boundary, is most of what you wanted from a service contract in the first place. It is just enforced by the schema now instead of hoped for in a wiki.
The honest tradeoffs
A typed binary protocol is not free, and pretending otherwise is how teams get burned.
The wire is no longer human-readable. You cannot eyeball a request in the browser network tab or curl an endpoint and read the JSON. Debugging needs tooling that speaks the protocol and reflects the schema, and that tooling has to be in place before you need it at 2 a.m., not after.
The browser is still REST's territory. Native gRPC does not run from a browser without a proxy layer (gRPC-Web), so the public, edge-facing surface of most systems stays HTTP and JSON. The realistic architecture is not gRPC everywhere. It is gRPC for the internal mesh and REST at the edge, with one boundary where the two meet.
And code generation is a build-time dependency you now own across every language in the fleet. The generated code has to be regenerated, versioned, and distributed. The .proto files need a home, an ownership model, and a review process, because they are now the most load-bearing artifact in the system. A schema that anyone can change carelessly is worse than no schema at all.
The takeaway
Untyped JSON-over-HTTP asks two services to agree and trusts them to keep agreeing. Contract-first asks them to agree once, in a schema, and then makes the compiler enforce it forever after.
The choice is not gRPC versus REST as rival religions. It is matching the boundary to its traffic. The public edge, with clients you do not control, wants REST's openness and reach. The internal mesh, with services you do control, wants the discipline of a typed contract that fails loudly at build time instead of quietly in production.
The deeper principle outlives the protocol. A boundary defined only by convention is a boundary that drifts. A boundary defined by a schema is a boundary you can change on purpose.
Stop describing the contract. Define it, generate from it, and let the build break when someone forgets it exists.
Sources
- Roy T. Fielding, "Architectural Styles and the Design of Network-based Software Architectures" (Doctoral dissertation, UC Irvine, 2000): https://roy.gbiv.com/pubs/dissertation/top.htm
- gRPC project (Google, open-sourced 2015): https://grpc.io/docs/what-is-grpc/introduction/
- Protocol Buffers (Google, open-sourced 2008): https://protobuf.dev/
- Ian Robinson, "Consumer-Driven Contracts: A Service Evolution Pattern" (martinfowler.com, 2006): https://martinfowler.com/articles/consumerDrivenContracts.html
- Sam Newman, "Building Microservices" (O'Reilly, 1st ed. 2015).
- Pat Helland, "Life beyond Distributed Transactions: an Apostate's Opinion" (CIDR 2007; ACM Queue 2016).
- Akka HTTP documentation (Lightbend / Akka): https://doc.akka.io/libraries/akka-http/current/
- Akka gRPC documentation (Lightbend / Akka; since 1.0.0, 2020-06-17): https://doc.akka.io/libraries/akka-grpc/current/
- gRPC-Web (https://github.com/grpc/grpc-web): the proxy layer that lets browser clients reach gRPC services.