Most discussions of ReAct frame it as a clever prompting technique.
It isn’t.
ReAct is the first time we gave language models a structure for intelligence rather than an instruction.
Thought alone was drifting.
Action alone was thrashing.
ReAct turned the two into a feedback system.
This post explains the architecture.
1. The ReAct Contract
Every agent needs three fundamental capacities:
- To think
- To act
- To learn from the consequences of its actions
CoT gave us the first.
Tool-using agents gave us the second. These agents received observations back from their actions, but lacked the explicit reasoning traces to systematically learn from them.
ReAct completes the picture by adding that third capacity: structured learning from consequences.
Thought → Action → Observation → Updated Thought → Action → …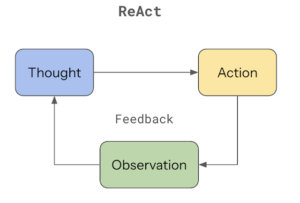
A narrow sequence.
A wide implication.
ReAct gives the model a workspace — a kind of externalized working memory where it can:
- form hypotheses
- test them against reality
- adjust course based on what the world returns
This is the foundation of agency.
2. Thoughts Are Not Explanations — They Are Computation
Humans often misunderstand ReAct’s “thoughts” as explanations for the reader.
They’re not.
Thoughts in ReAct are internal computations.
Fragments of working memory.
Deliberate steps that signal how the model is evaluating its choices.
This is the architectural shift:
Thought is no longer the answer.
Thought becomes the internal state that guides the next action. It is the explicit function call that directs the tool.
And because thoughts are visible, not implicit:
- we can inspect reasoning
- we can supervise it
- we can debug it
- we can constrain it
- and we can correct it
This created the first agent architecture that’s auditable by design.
3. Why Grounding Eliminates Hallucination
ReAct’s most surprising result wasn’t better accuracy.
It was the collapse of hallucination rates.
In HotpotQA, Chain of Thought produced false statements in more than half its reasoning traces.
ReAct reduced that to zero because it binds the model’s reasoning to reality.
In their human analysis study of randomly selected examples, ReAct achieved 0% hallucination failures compared to CoT's 56%. While ReAct had some false positives (6%), where reasoning was flawed despite correct facts, the elimination of hallucinated content represented a fundamental architectural breakthrough.
Here’s the architecture-level explanation:
Hallucinations occur when the model is allowed to invent knowledge without environmental correction.
ReAct breaks that loop.
Every Thought is followed by an Action.
Every Action produces an Observation.
And every Observation corrects the next Thought.
Internal fantasy has no room to grow.
This is why even smaller ReAct-enabled models outperform larger CoT models:
ReAct replaces parameter-driven knowledge with environment-driven clarity.
It’s not a prompt trick.
It’s architectural grounding.
4. The ReAct Loop Explained Like an Architect: Function and Flow
Let’s break down the loop in terms of system behavior.
1. Thought: Hypothesis generation
The model produces a candidate direction.
Examples:
- “I should find the actor’s birthplace.”
- “This question requires two hops.”
- “Let me retrieve context first.”
This is planning, not guessing.
2. Action: Execute a grounded step
The Thought chooses a tool: search, retrieval, navigation, lookup.
The system interacts with an external world — not an imagined one.
3. Observation: External feedback
The environment pushes back.
The agent learns what the world actually contains.
4. Updated Thought: Reflection and adjustment
The agent revises.
It explains what worked, what didn’t, and what to do next.
This is what a real agent feels like in motion:
Thought: I should check who played Bilbo.
Action: Search["Bilbo actor"]
Observation: Result shows 'Ian Holm' and 'Martin Freeman'.
Thought: The question involves the older films; I should focus on Ian Holm.
Action: Search["Ian Holm birthplace"]
Observation: “London, England.”
Final Answer: Ian Holm was born in London.
This is not linear reasoning.
This is iterative correction.
A loop.
A negotiation between mind and world.
5. ReAct Under Load: How It Behaves in Real Environments
ReAct’s strength emerges under real-world stress:
1. HotpotQA (multi-hop reasoning)
CoT overthinks and commits to wrong chains.
ReAct tests each hop and prunes false paths early.
2. FEVER (fact verification)
CoT confidently invents facts.
ReAct grounds every claim against retrieved evidence.
3. ALFWorld (long-horizon tasks)
Act-only agents flail.
ReAct creates and revises plans as it explores.
ReAct achieved a 78.4% success rate with GPT-3, outperforming act-only baselines by a significant margin through its ability to reason about action outcomes and adjust strategies mid-task.
4. WebShop (noisy search environment)
ReAct adapts search queries based on poor results — something a static planner can’t do.
Across all domains, the pattern is consistent:
ReAct performs better because it wastes less time believing wrong things.
6. ReAct's Real-World Limitations
ReAct isn't perfect. The paper identifies several challenges:
- Search dependency: Poor search results can derail the entire reasoning chain
- Infinite loops: The model can get stuck repeating the same thoughts and actions
- Context limits: Long trajectories can exceed context windows
- Cost: More tokens = higher API costs
The best performing approach actually combines ReAct with CoT, allowing the model to leverage both external grounding and internal knowledge. This hybrid approach (ReAct + Self-Consistency) outperformed either method alone — on HotpotQA, ReAct+SC achieved 78.5% compared to ReAct-only at 69.4%.
7. What ReAct Reveals About Intelligence
ReAct succeeded because it captured something true about cognition:
Intelligence emerges from the interplay between intentions and consequences.
This is why humans don’t think everything through in advance.
We externalize our reasoning:
- by acting
- by observing
- by adjusting
ReAct mirrors that adaptive loop.
A mind that never meets resistance grows fragile.
A mind that confronts reality becomes capable.
Agents needed resistance — the world pushing back.
ReAct provided the first structured way for that to happen.
8. The Quiet Power Behind ReAct
ReAct isn’t the final form of agent design.
But it set the architectural precedent:
- visible reasoning
- grounded actions
- feedback-driven correction
- structured trajectories
- auditable internal state
This is why frameworks like LangChain, LangGraph, AutoGen, and OpenAI’s function-calling agents all whisper the same underlying principle:
Agents must think inside the environment, not above it.
ReAct didn’t create autonomy.
It created the conditions under which autonomy becomes learnable.
Closing: Why Part III Matters
Now that we’ve mapped the architecture, the next post takes you from theory to practice:
Part III — Building Your First ReAct Agent (LangChain Implementation + Architectural Notes)
We’ll build a working ReAct agent — but more importantly, we’ll dissect it the way an architect would:
- why certain prompts matter
- how tools shape the agent’s reasoning
- how to avoid infinite loops
- how to evaluate trajectories
- how to design tasks the agent can actually solve
This is where the loop becomes real.