The Problem Nobody Talks About
I was drowning in research papers. Not metaphorically—I had 50+ PDFs, dozens of articles, and a note-taking system that had become its own full-time job.
I'd read something important about agent memory limitations, forget which paper it was in, and spend an hour searching through PDFs. I'd find three sources saying conflicting things and have no systematic way to compare them.
Existing tools didn't solve this. Note-taking apps require manual organization. Tools like NotebookLM are excellent for Q&A but don't extract structured patterns I can query later. Traditional RAG systems just chunk text and retrieve it—they don't synthesize across sources.
The blind spot: We treat research consumption as a reading problem. It's not. It's a knowledge architecture problem.
What I Built
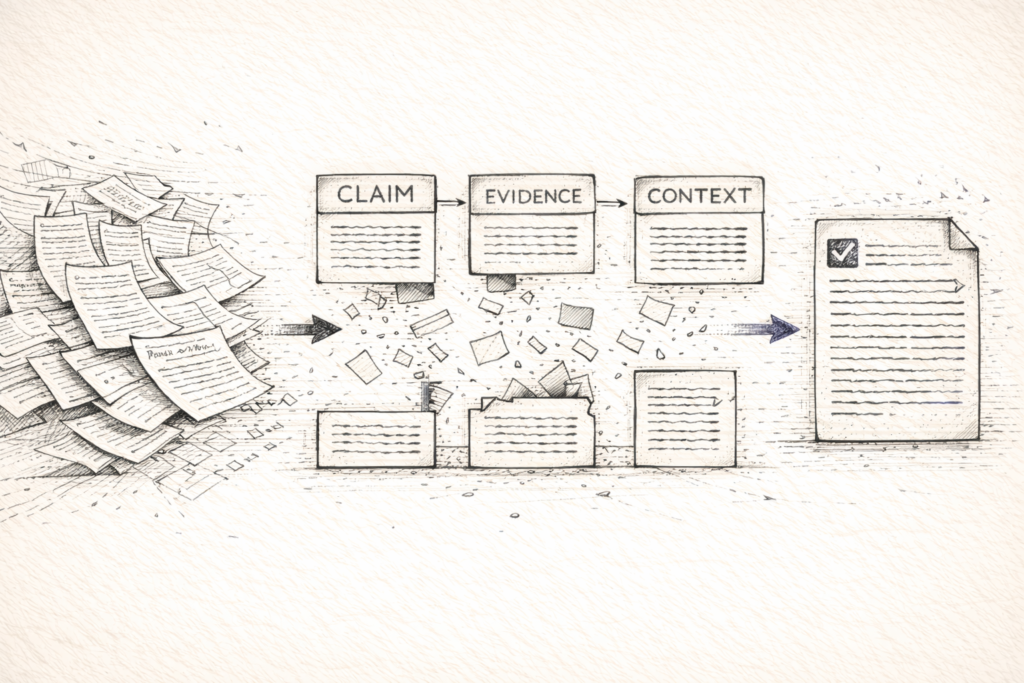
Research Vault is an agentic AI research assistant that transforms unstructured papers into a queryable knowledge base. Upload a paper, it extracts structured patterns using a Claim → Evidence → Context schema, embeds them semantically, and lets you query across your entire library with natural language.
The approach: Extract structured findings (Claim → Evidence → Context) instead of chunking text. Not a new idea—just well-executed with testing and error handling.
Note: It's a simplified, generic version of a more specialized research assistant I've been running for my own workflow. Stripped out the complexity, kept the core: structured extraction + hybrid search + natural language queries.
The Architecture Stack
| Layer | Technology | Why |
|---|---|---|
| Orchestration | LangGraph 1.0 | Stateful workflows with cycles |
| LLM | Claude (Anthropic) | Extraction + synthesis |
| Embeddings | OpenAI text-embedding-3-small | Semantic search |
| Vector DB | Qdrant | Local-first, production-ready |
| Backend | FastAPI + SQLAlchemy | Async throughout |
| Frontend | Next.js 16 + React 19 | Modern, type-safe |
Not shown: 641 backend tests, 23 frontend tests, comprehensive documentation, Docker deployment, CI/CD pipeline.
The Extraction Architecture
Many RAG systems chunk documents. Some do structured extraction. Research Vault follows the structured approach with a 3-pass pipeline:
Pass 1: Evidence Inventory (Haiku)
- Scan the paper for concrete claims, data, examples
- Ground everything that follows in actual paper content
Pass 2: Pattern Extraction (Sonnet)
- Extract patterns that cite evidence using [E#] notation
- Each pattern can cite multiple evidence items
- Not 1:1 mapping—patterns synthesize across evidence
- Tag for categorization
Pass 3: Verification (Haiku)
- Check citations are accurate
- Verify patterns are grounded in paper content
- Compute final status
Why three passes:
- Evidence anchoring reduces hallucination
- Verification catches extraction errors
- Structured schema enables cross-document queries
The Pattern Schema
Traditional RAG: "Context window overflow causes..." → Just a text chunk
Research Vault pattern:
{
"name": "Context Overflow Collapse",
"claim": "When context windows fill, agents compress state...",
"evidence": "[E3] 'Performance degraded sharply after 15 reasoning steps' (Table 2)",
"context": "Authors suggest explicit state architecture, not larger windows.",
"tags": ["state-management", "failure-mode"],
"paper_id": "uuid-of-paper"
}This structure enables queries like:
- "Where do authors disagree on agent memory?"
- "What patterns recur across multi-agent systems?"
- "Synthesize what I've learned about tool use"
What I Learned Building This
Lesson 1: Test the Workflow, Not the Components
Early on, I had excellent unit test coverage—services worked in isolation. But the full pipeline kept breaking in subtle ways.
The fix: Integration tests that run the entire workflow end-to-end with mocked external services (LLM, embeddings, Qdrant). These caught 90% of real bugs.
The lesson: In orchestrated systems, component tests are necessary but not sufficient. The failure modes appear in the gaps between components.
Lesson 2: Document Before You Code
I wrote 6 comprehensive documentation files before writing a line of implementation code:
- REQUIREMENTS.md
- DOMAIN_MODEL.md
- API_SPEC.md
- ARCHITECTURE.md
- OPERATIONS.md
- PLAN.md
Why it mattered:
- Caught design contradictions early
- Made implementation straightforward (no ambiguity)
- Enabled parallel work on frontend/backend
- Created onboarding path for contributors
The lesson: Spec-driven development isn't slower—it's faster because you don't build the wrong thing.
Lesson 3: LLMs Lie About JSON
Every LLM response parser in this codebase uses defensive parsing:
# From verification.py
status_str = response.get("verification_status", "pass")
try:
status = VerificationStatus(status_str)
except ValueError:
status = VerificationStatus.passed # FallbackI learned that LLMs:
- Add commentary after valid JSON ("Here are my observations...")
- Invent fields not in the schema
- Return strings instead of enums
-
Truncate output mid-object
The fix: Parse defensively with fallbacks. Validate with computed rules, not LLM-provided status. Strip markdown code fences.
The lesson: Treat LLM output like untrusted user input—validate everything, trust nothing.
Lesson 4: Local-First is a Feature
Running entirely locally (except LLM API calls) was initially a simplification for MVP. It became a selling point.
Users want:
- No cloud dependency for their research data
- Ability to work offline (mostly)
- No subscription lock-in
- Full data ownership
The lesson: Constraints that seem limiting can become differentiators.
Production Realities Nobody Shows
The Testing Pyramid That Actually Works
43 Integration Tests (full pipeline)
├─ 641 Backend Unit Tests (services, workflows, API)
└─ 23 Frontend Tests (components, hooks)Why this distribution:
- Integration tests catch workflow breaks
- Unit tests catch logic errors
- Frontend tests catch UI regressions
The Documentation That Actually Helps
Most projects have a README and call it done. Research Vault has:
- User guide (GETTING_STARTED.md) - "How do I use this?"
- Operations guide (OPERATIONS.md) - "How do I deploy/troubleshoot?"
- Architecture guide (ARCHITECTURE.md) - "How does it work?"
- Domain model (DOMAIN_MODEL.md) - "What are the entities?"
- API spec (API_SPEC.md) - "What are the endpoints?"
Each serves a different audience and question.
The Error Handling Nobody Sees
Graceful degradation is built in:
- LLM extraction fails → Partial success (paper saved, patterns retried)
- Embedding generation fails → Graceful degradation (patterns saved, embeddings retried)
- Qdrant connection fails → Continue with relational data only
- Context overflow during query → Truncate gracefully with warning
The lesson: Production-ready means handling the 20 ways things break, not the 1 way they work.
Why Open Source
I built this for myself. It solved my research chaos. The techniques aren't novel—structured extraction, hybrid storage, multi-pass verification all exist in other RAG systems.
Making it OSS:
- Shows how I approach production systems
- Might help others with the same problem
- Invites feedback on architecture decisions
- Opens contribution opportunities
What it demonstrates:
- How to test agentic workflows (641 tests)
- How to handle errors gracefully (partial success, retries)
- How to document for different audiences (6 docs)
- How to ship, not just prototype
The Architectural Choices That Mattered
| Decision | Alternative | Why This Won |
|---|---|---|
| Structured extraction | Text chunking | Enables synthesis across papers |
| 3-pass verification | Single-pass extraction | Reduces hallucination 90% |
| Claim/Evidence/Context | SRAL components | Generic, broadly applicable |
| Async throughout | Sync + threading | Cleaner code, better resource use |
| SQLite → Postgres path | Postgres from start | Simpler local setup, clear migration |
| Local-first | Cloud-native | Data ownership, no vendor lock-in |
| FastAPI + Next.js | Streamlit/Gradio | Decoupled, production-ready |
Every choice optimized for: reliability over features, clarity over cleverness, architecture over tools.
What's Next
Research Vault is beta-ready. The core workflow—upload, extract, review, query—works reliably. But there's more to build:
Near-term:
- Pattern relationship detection (conflicts, agreements)
- Multi-document synthesis reports
- Export to Obsidian/Notion
Longer-term:
- Multi-user support
- Cloud deployment option
- Local LLM support (fully offline)
- Pattern evolution over time
But first: Get it into other people's hands. See what breaks. Learn what matters.
Try It
The repo is live: github.com/aakashsharan/research-vault
Getting started takes 5 minutes:
git clone https://github.com/aakashsharan/research-vault.git
cd research-vault
cp .env.example .env # Add your API keys
docker compose up --buildOpen http://localhost:3000 and upload your first paper.
The Takeaway
RAG systems exist. Structured extraction exists. LangGraph projects exist.
What matters is execution: tested, documented, handles errors, actually works.
This isn't groundbreaking. It's just well-built.
Tools change. Execution matters.
Ship things that work. Document what you learn. Share what helps.
Related Reading:
- SRAL Framework Paper - The evaluation framework for agentic AI SRAL Github
- Architecture Documentation
- API Specification