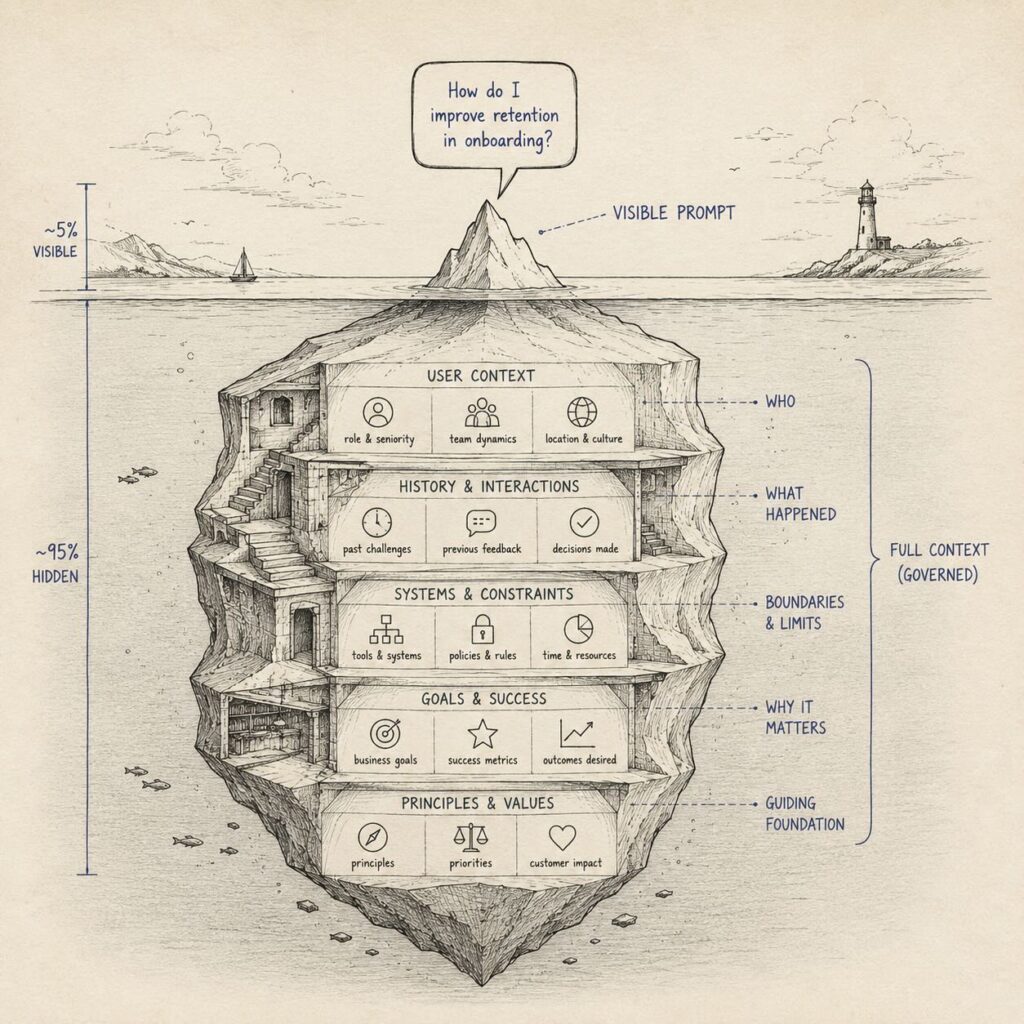
"Prompt engineering" is the wrong mental model for where agents are going.
It made sense when the product was a chat box.
It breaks the moment you ask an agent to persist, to improve over time, and to operate across channels, projects, and weeks.
The field already sensed this and quietly changed the word.
Prompt engineering is syntax. Context engineering is governance.
The center of gravity moved
This is not one company's idea. In June 2025, Shopify's CEO Tobi Lutke publicly argued that "context engineering" was a better description of the core skill than "prompt engineering," and Andrej Karpathy amplified the point: in any serious LLM application, the real work is filling the context window with the right information for the next step, not wording a clever prompt. Within the same two weeks, LangChain framed it as "building dynamic systems to provide the right information and tools in the right format," and Cognition, the team behind Devin, called it "the next level of prompt engineering." By September 2025, Anthropic had brought the framing into its own engineering guidance, reframing the question from wording to "what configuration of context is most likely to generate our model's desired behavior."
That is a real shift in the center of gravity. The serious agent builders adopted a better name for the skill.
But much of the popular framing starts with assembly: fill the window with the right information for the next step. The production problem goes further, into ownership, policy, and lifecycle. Governing what persists across many steps, sessions, and weeks is a different problem. The first is about assembly. The second is about state.
This post is about the second.
Problem: durable agents fail for boring reasons
Long-lived agents do not fail because the model cannot reason.
They fail because state is unmanaged.
- Conversations grow until context windows blow up.
- Old instructions linger and conflict with new instructions.
- Preferences drift, or get overwritten by noise.
- Retrieval becomes a slot machine.
- Tool outputs bloat the prompt and dominate the budget.
- Nobody can answer: "Why did the agent believe that?"
When the system fails, people reach for a better prompt.
That is like debugging a distributed system by rewriting the README.
You might get a short-term improvement.
You will not get reliability.
Blind spot: most "memory" features are not memory
Start with the thing everyone already calls memory.
Most platforms treat memory like a feature:
- a
/remembercommand - a vector store
- "top-k memories" injected into the prompt
That is not learning.
That is a write API plus retrieval.
Learning requires a lifecycle:
- deciding what counts as state
- consolidating experience into durable representations
- governing what is allowed to persist
- assembling the right context for the next action under a budget
In other words, learning requires context engineering in the second, harder sense.
Architectural truth: context is an operating system
If you want durable agents, treat context like an operating system.
Not a longer prompt.
An OS has:
- state
- policies
- permissions
- scheduling
- isolation boundaries
- observability
- and a way to recover when things crash
Agent context needs the same.
The useful artifact is not a prompt. It is a contract: a declaration of what state means, rules for how state is modified, and constraints on what is allowed.
Concretely, each class of memory in that contract has a shape. A user preference, for instance:
- Type: durable preference
- Owner: the profile subsystem, not the main loop
- Write policy: updated only on explicit, repeated signal, never from a single offhand remark
- Evidence: the interaction that justified the change
- Retention: persists until contradicted, then superseded
- Rollback: revertible to the prior value, with the change logged
Write that for every class of state you let an agent keep, and you have a context contract. Skip it, and you have a text file that grows.
That is a control plane move.
This maps directly to two principles I keep coming back to.
The first: context is an operating system. Identity, continuity, and policy live in context. Treat it as governed state, not a longer prompt.
The second: the harness is the product. Models commoditize. The moat shifts to the runtime: policy, approvals, audit trails, artifacts, sandboxes, memory lifecycle.
A contract without the harness is philosophy. A harness without the contract is chaos.
Durable agents require both.
What context ownership actually implies
Context ownership has concrete implications. None of them are exotic. They are the same controls any stateful system needs.
1) Versioned state, not invisible state
If memory is valuable, it must be inspectable.
A minimum bar:
- you can view it
- you can diff it
- you can revert it
- you can attribute where it came from
If you cannot do those things, the agent is not "learning."
It is accumulating a pile of ungoverned text.
2) Scheduled consolidation, not ad hoc notes
Durable context cannot be written only at interaction time.
The main agent is busy:
- responding
- calling tools
- making decisions under latency and budget constraints
The consolidation step belongs in the background.
Call it background reflection, sleep-time compute, or maintenance jobs.
Either way, the system needs a periodic process that:
- reviews recent activity
- promotes the signal
- compresses the noise
- and rewrites memory artifacts so the next session starts clean
3) Budgets and drop policies, not "stuff it all in there"
Context windows are getting bigger, but that does not remove the need for budgets.
This is measured, not theoretical.
Chroma's "context rot" study found that the 18 models it tested grew less reliable as input length grew, even on simple retrieval, and that distractors resembling the answer amplify the decline. Treat that vendor framing as directional.
It lines up with peer-reviewed work. NoLiMa, accepted at ICML 2025, reported many models falling below half their short-context accuracy by 32K tokens, with GPT-4o dropping from 99.3 percent to 69.7 percent.
The "lost in the middle" effect (Liu et al., 2023) is the named version of the same problem: models use the start and end of a long context far better than the middle.
Bigger context simply postpones the crash, while making it more expensive.
So context engineering means:
- hard token budgets per memory class
- recency and scope rules
- intent-scoped retrieval
- and explicit drop policies
4) Governance at the point of execution
Every memory write is an irreversible action unless you make it reversible.
So treat memory writes like any other sensitive tool:
- Intent: what are we changing, and why?
- Authorization: is this class of memory allowed, or does it require approval?
- Evidence: what experience supports the update?
- Reversibility: can we revert cleanly?
This is not bureaucracy.
This is how you keep a long-lived system from drifting into contradiction.
Why labs optimizing coding benchmarks is a real problem
There is a structural reason memory lags.
Coding benchmarks reward short-lived excellence. A SWE-bench-style run scores whether a model resolves an issue inside a single session, under a fixed context.
They measure:
- local problem solving
- within one session
- under a fixed context
They do not measure whether an agent can:
- remain coherent over months
- improve from experience
- keep a stable identity across model swaps
- or avoid accumulating false beliefs in memory
A capability the scoreboard ignores tends to lag, and memory formation is that capability.
The market corrects this only when people run agents continuously and discover the failure modes are state failures.
That is when "prompt engineering," in either sense, stops being the lever.
The takeaway
The field found a better name in 2025. The work now is to mean the harder thing by it.
Context engineering is not only assembling the right window for the next step. It is owning context as durable, governed state: principles and tooling for what persists, how it changes, and who is allowed to change it.
That is why the next generation of moats will look less like model choice and more like:
- memory lifecycle
- governance primitives
- and control planes for state
State is the foundation, not an afterthought. It is the first of the four questions I ask about every agent, and the reason is simple.
Reasoning depth cannot exceed state stability.
That's architecture.
Sources
- Tobi Lutke, on "context engineering" (X, June 2025): https://x.com/tobi/status/1935533422589399127
- Andrej Karpathy, on "context engineering" (X, June 2025): https://x.com/karpathy/status/1937902205765607626
- Harrison Chase / LangChain, "The rise of context engineering" (June 23, 2025): https://blog.langchain.com/the-rise-of-context-engineering/
- Walden Yan / Cognition, "Don't Build Multi-Agents" (June 2025): https://cognition.com/blog/dont-build-multi-agents
- Anthropic, "Effective context engineering for AI agents" (September 2025): https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
- Chroma, "Context Rot: How Increasing Input Tokens Impacts LLM Performance" (July 2025): https://research.trychroma.com/context-rot
- Modarressi et al., "NoLiMa: Long-Context Evaluation Beyond Literal Matching" (ICML 2025): https://arxiv.org/abs/2502.05167
- Liu et al., "Lost in the Middle: How Language Models Use Long Contexts" (TACL 2024): https://arxiv.org/abs/2307.03172
- Jimenez et al., "SWE-bench: Can Language Models Resolve Real-World GitHub Issues?" (arXiv 2310.06770): https://arxiv.org/abs/2310.06770