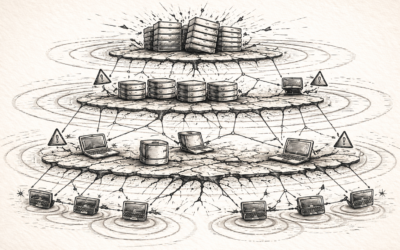
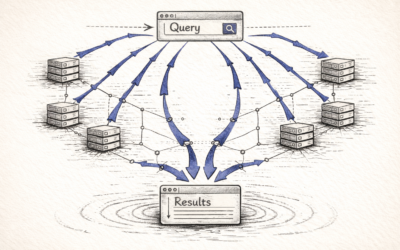
The Hidden Complexity Behind Scaling Dense Vector Search A systems-level explanation for engineers, architects, and anyone building RAG, search, or agent infrastructure. Dense retrieval looks clean on paper. You take an embedding model,... AI Infrastructure 26/11/2025
Distributed Vector Search: How Real Vector Databases Scale Beyond One Machine Why dense search becomes a routing, sharding, and distributed-systems problem Vector search looks simple when everything fits on one machine. It becomes a different discipline... AI Infrastructure 25/11/2025
The Write Path in Vector Databases (It’s a Distributed Systems Problem) (Where Dense Search Becomes a Distributed Systems Problem) Most content about vector databases focuses on the glamorous part: fast queries, clever indexing, tight cosine similarity... AI Infrastructure 24/11/2025
Akka Edge: Shaping the Future of Industry with Edge Computing Introduction: navigating the digital revolution with Akka at the edge capabilities In the ever-evolving digital technology landscape, a significant shift is taking place, with edge... Distributed Systems 22/01/2024
Mastering gRPC Advanced Techniques: A Comprehensive Guide – Part II Alrighty then! Let's pick up from where we left off in Part 1. Buckle up, and let's dive right in! Implementing gRPC Services Server-side Implementation... Distributed Systems 22/01/2022
Mastering gRPC Basics: A Comprehensive Guide – Part I Understanding gRPC gRPC and its purpose gRPC is a modern Remote Procedure Call (RPC) framework. But what does that mean? Think of it like this:... Distributed Systems 13/01/2022
The Bulkhead Pattern: Designing Systems That Refuse to Drown Updated December 2025 to reflect modern autonomous and agentic systems Executive Summary Most distributed systems don’t fail catastrophically. They fail quietly. Threads saturate. Queues fill.... Distributed Systems 20/04/2019