Organizations are harnessing the power of artificial intelligence (AI) and machine learning (ML) to gain insights into customer behavior, operational efficiencies, and numerous other business challenges. As a result, companies are making substantial investments in data science technology and teams to develop and train analytical models. While these investments pay off, the real jackpot lies in operationalizing AI/ML practices.
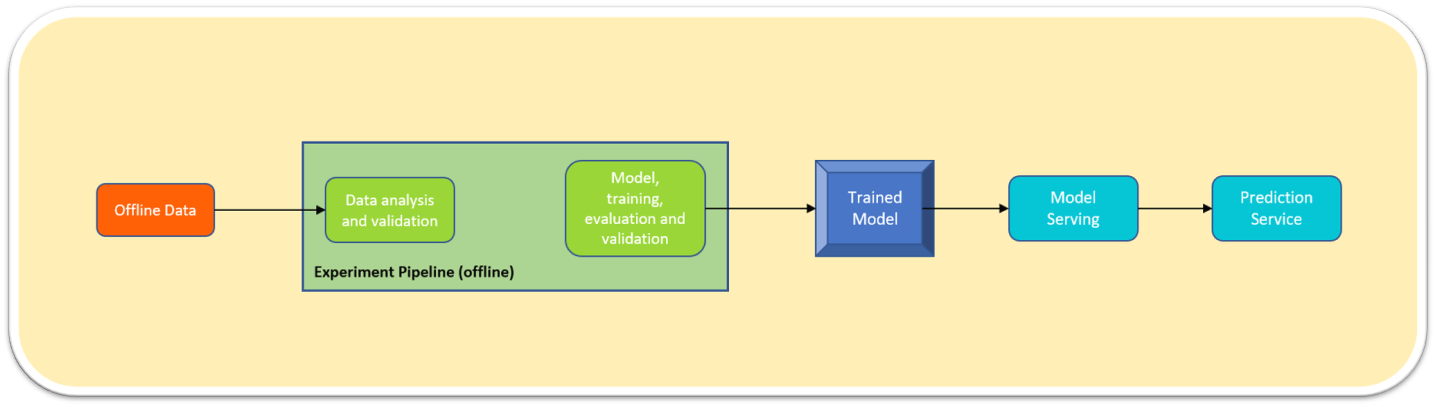
Currently, most enterprises are stuck performing manual, script-driven ML tasks. The following diagram illustrates a typical example of such a manual model:
-
Data Scientists chomp on historical data, going through manual processes like data analysis, feature engineering, model training, testing, and validation.
-
Once the model is trained, it's handed over to engineers as a precious artifact.
-
This artifact is then deployed on an infrastructure like a conquering hero.
However, this process is riddled with challenges and constraints:
-
Data is manually shoved into and yanked out of the models.
-
Whenever models change, IT assistance is summoned like a genie.
-
Data scientists feast on offline data (data at rest) for modeling. There's no magical data pipeline to quickly deliver data in real-time and in the right format.
-
Data modeling, lacking a CI/CD pipeline, has all tests and validations done manually through scripts or notebooks. This leads to coding blunders and wonky models, causing a nosedive in predictive services. Say hello to compliance issues, false positives, and lost revenue.
-
Manual processes don't have active performance monitoring. Imagine your model is misbehaving in production, and you're left wondering why and how?
-
Additionally, manual model processing can't make comparisons using specific metrics of your current production model (e.g., A/B testing).
Building an Automated MLOps Pipeline
Traditionally, developing, deploying, and continuously improving an ML application has been a complex dance, causing many organizations to miss out on the perks of automating data pipelines.
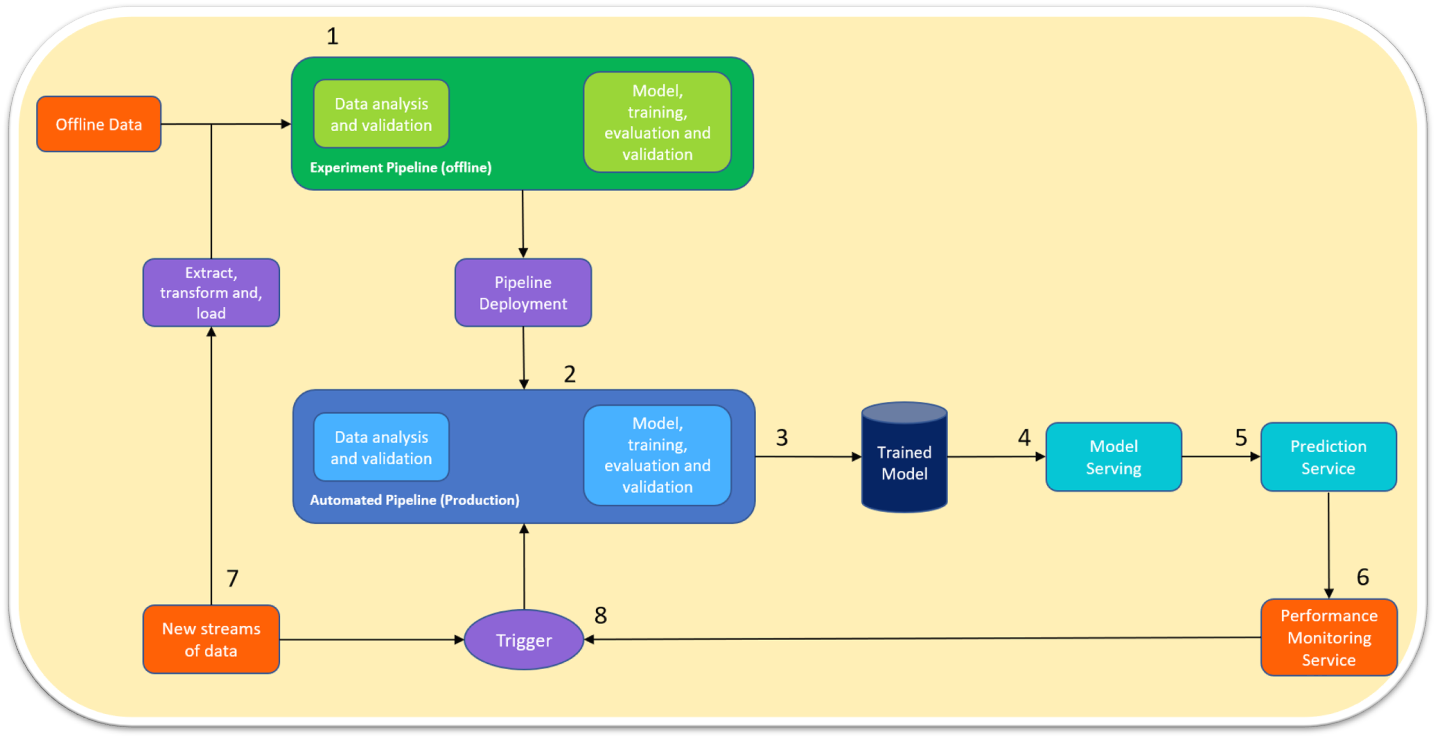
To tackle these challenges, an ML operations pipeline (MLOps) is the knight in shining armor. Check out what a typical MLOps pipeline looks like below:
-
Data Scientists munch on offline data for data analysis, modeling, and validation.
-
Once the model is pushed through the pipeline deployment, it's passed onto the automated pipeline. If there's any new data, it's extracted and transformed for model training and validation like a well-oiled machine.
-
Once a model is trained or outperforms the one already serving in production, it's ushered into a repository.
-
The trained model is then picked up and deployed in production like a champ.
-
The prediction service spews out labels. This service could have multiple consumers lining up for a taste.
-
A performance monitoring service gobbles up this data and checks for any performance hiccups.
-
If there's a new stream of data rolling in, it's sent through an ETL pipeline, eventually reaching data scientists. It also gives the trigger service a buzz.
-
The trigger service can be scheduled depending on the use case. We've seen the following scenarios in enterprises:
-
When there's a performance slump in the model.
-
When there's fresh incoming data.
-
For more information, swing by Google MLOps.