Most teams still evaluate coding agents with one question.
Can it write the code?
That question made sense when the product was autocomplete. You asked for a function, the model produced a function, and you judged the function. Correctness, style, tests passed, benchmark score. The artifact was the whole story.
It is the wrong question now.
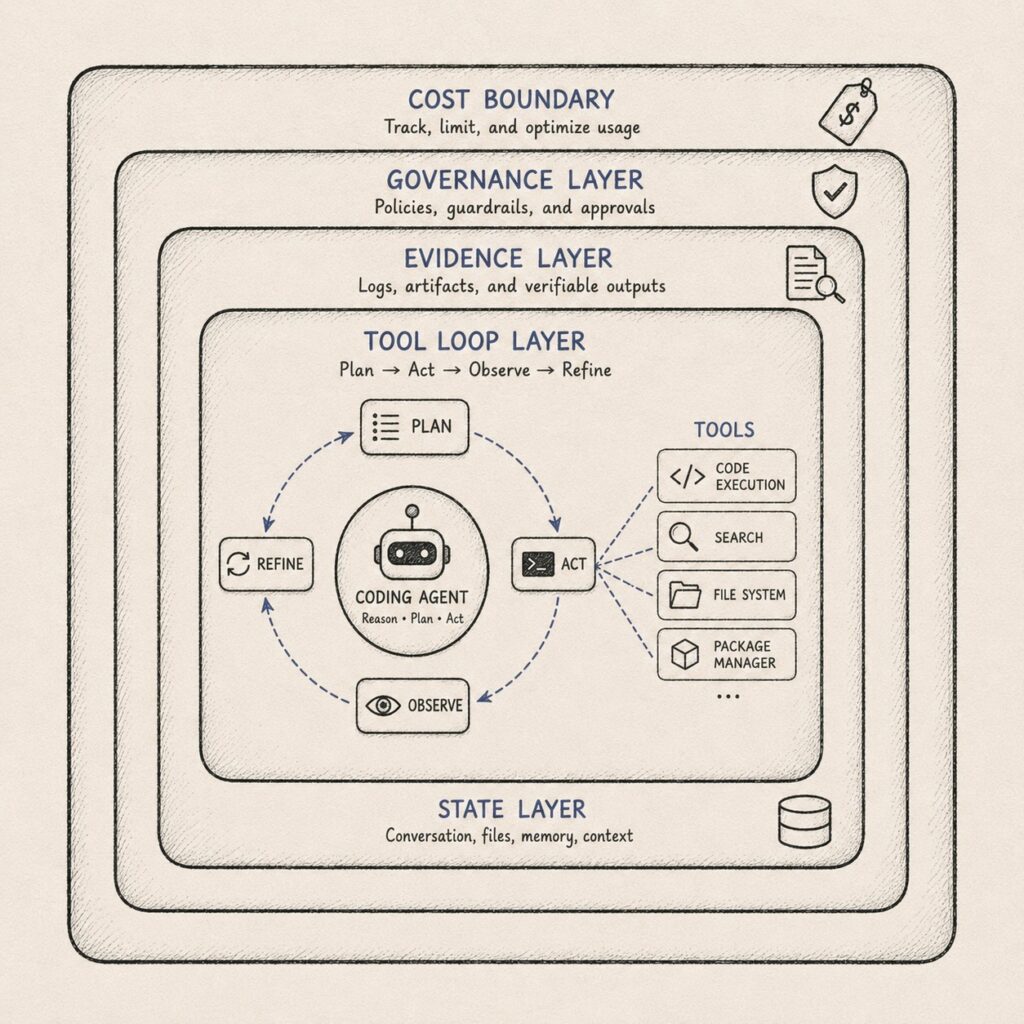
A modern coding agent does not just answer. It acts. It inspects files, edits patches, runs tests, reads logs, calls package managers, hits tool servers, compares diffs, recovers from failures, and continues across many turns. The output is not a function. It is a work trace.
That changes what you are buying, and it changes what you should measure.
You are not buying a model. You are buying a model plus the runtime it acts through. And the runtime is where most of the reliability, and most of the failure, actually lives. This is the shift I called the agent runtime era: the differentiator moved from the model to the runtime around it.
So the evaluation question becomes: which model-runtime pair completes our work, with evidence, at bounded cost, and acceptable operational risk?
Here is how to answer it.
Measure state continuity
Coding work depends on continuity. The agent needs to remember why a file was touched, which hypothesis failed, which error was environmental, which test was skipped, and which assumption still needs review.
If that state lives only in the conversation, it is fragile. If it lives only in hidden reasoning, it is hard to govern. If it lives in structured artifacts, checkpoints, summaries, diffs, and run records, it becomes reviewable. That is context engineering applied to evaluation: state you can see, diff, and revert, the property an append-only event log gives a system by design.
State is even starting to show up as a model feature. Kimi K2.7 Code, for example, forces a preserve_thinking mode that the model card says retains full reasoning content across multi-turn interactions to improve coding-agent performance. That can help a model stay coherent. But coherence is not the same as a state contract, and production needs the contract.
So test the contract, not the vibe:
- Does the agent preserve the reason for a change across turns?
- Does it track failed hypotheses instead of repeating them?
- Does it remember constraints after the context is compacted?
- Does it recover after a restart?
An agent that loses the thread halfway through a real task will look brilliant in a demo and unreliable in your repo.
Measure tool-loop reliability
Coding agents do not solve work in a clean text stream. They solve it through an alternating loop: inspect, infer, edit, execute, observe, revise, verify, report.
The next token is no longer the only decision that matters. The next action matters just as much. Should the agent read another file, run a narrow test or the full suite, call a tool server, or stop and ask for approval?
This is where the benchmark gap becomes visible. A model can score well on isolated coding problems and still fail as a tool-using worker. It can produce plausible patches while wasting tool calls, ignoring failed commands, losing track of changed files, or claiming success without checking.
So measure the loop, not just the patch:
- Does it inspect before editing?
- Does it run the right tests, not just any test?
- Does it treat a failing command as evidence rather than noise?
- Does it stop when tool output contradicts its plan?
A strong model inside a sloppy loop is a liability. The loop is part of the product.
Measure evidence discipline
An agent that says "done" is not the same as an agent that shows its work.
In a real engineering process, you do not accept a change because someone is confident. You accept it because there is a diff, a test command, and a result you can inspect. The same standard applies to an agent, and most evaluations skip it entirely.
So make evidence a graded requirement:
- Does it report the exact files it changed?
- Does it include the test commands it ran and their output?
- Does it distinguish verified work from assumed work?
- Does it leave artifacts a reviewer can actually open?
An agent that cannot produce evidence has not finished the task. It has finished talking about the task.
Measure governance
The moment an agent can edit files, run commands, and hit external services, it inherits every failure mode of an actuator with permissions. The question is no longer whether it is smart. It is whether it is contained.
So measure the boundaries:
- Does it request approval before destructive or irreversible operations?
- Does it respect read-only versus write scopes?
- Does it avoid exposing secrets?
- Does it keep a clear rollback path?
This is the part teams skip because it is unglamorous, and it is the part that turns a helpful agent into an incident. Governance is not a setting you add later. It is a property you evaluate up front.
Measure economics
A coding agent that gets the answer after a thousand tool calls and a budget overrun is not a good agent. It is an expensive one that happened to work.
So measure cost as a first-class result, not an afterthought:
- How many tool calls did the task actually need?
- How many tokens did the run consume?
- How much context was retained versus rebuilt?
- Did the agent escalate effort only when the uncertainty earned the cost?
Bounded cost is part of correctness in production. An agent that cannot stay inside a budget cannot be trusted to run unattended, which is the whole point of an agent.
Why the harness is now part of model quality
Here is the uncomfortable part for anyone who wants a clean leaderboard.
The same model can feel competent or erratic depending on the runtime around it. A good harness preserves useful state, exposes the right tools, blocks dangerous actions, records evidence, and keeps the agent from confusing activity with progress. A weak harness makes a strong model look unreliable. I make the architectural case for treating that layer as infrastructure in The Harness Is the Control Plane.
The open-source project oh-my-pi is a clean illustration of how much engineering now lives in that layer. Its design treats the harness itself as the performance surface. Edits use content-hash anchors, so a patch against a stale file is rejected before it corrupts anything. The agent gets LSP operations for renames and diagnostics and DAP access to drive a real debugger instead of guessing from print statements. Subagents return schema-validated objects from isolated worktrees. A regex can abort the stream mid-generation, inject a rule, and retry when the model drifts off policy.
The project reports large effects from those interface choices: an edit-success jump from 6.7% to 68.3% for one model, a 61% output-token reduction for another, and a 2.1x pass-rate gain for a third. Treat those as project-reported harness metrics, not independent benchmark truth. But the architectural point stands on its own. If changing the edit format, tool surface, and retry path can move pass rate and token use that much, then a benchmark score is not measuring model intelligence alone. It is measuring the work interface the model is forced to inhabit.
Vendor evaluations now make this visible. Moonshot's Kimi K2.7 Code card notes that each model was run inside its own harness for comparison: Kimi through its own CLI, GPT-5.5 in Codex, Opus 4.8 in Claude Code, each at its high-effort setting. That is a reasonable way to run a practical comparison. It is also an admission that there is no such thing as an isolated model score anymore. You are always measuring model plus harness.
This is why coding-agent numbers are getting harder to read. When a score improves, what improved? The model, the tool policy, the context packer, the retry loop, the prompt, or the evaluation harness? Usually several at once. That does not make scores useless. It means the unit of competition has changed. The product is not model weights. It is the work system.
The benchmarks are already moving this way
If you want evidence that the category is shifting, look at what the newer benchmarks try to measure.
The Kimi K2.7 Code card separates ordinary coding benchmarks from a distinct agentic group. One of them, an in-house long-horizon benchmark, is described as spanning 17 professional scenarios and 610 evaluation points across software engineering, ML research, recruiting, trading, and marketing, run through an agent harness rather than a single prompt. Others evaluate realistic tool use across real server environments like GitHub, Postgres, and a browser, under explicit tool-call budgets and per-step token limits.
The exact scores are vendor-reported, and you should treat them that way. The signal is not the numbers. The signal is the shape. These benchmarks are no longer asking whether a model knows syntax. They are asking whether it can operate inside a tool environment and make progress over many steps without losing the thread.
That is the same set of questions you should be asking locally, against your own work.
The practical question
Raw benchmark rank will not tell you what you need to know. You need evaluations that look like your real work and grade the things that actually break: state across interruptions, tool loops under failure, evidence a reviewer can trust, boundaries that hold, and cost that stays bounded.
The question is not which model writes the best code in the abstract.
It is which model-runtime pair completes your work, leaves evidence, and stays inside its limits.
That question is harder to fake. It is also the only one that predicts what will happen when you let the thing run unattended in your codebase.
The model still matters. But you are not evaluating a model.
You are evaluating a runtime. Grade it like one.
Sources
- Moonshot AI, Kimi K2.7 Code model card, Hugging Face (created June 11, 2026; last modified June 12, 2026): https://huggingface.co/moonshotai/Kimi-K2.7-Code
- Moonshot AI, Kimi K2.7 Code README (raw): https://huggingface.co/moonshotai/Kimi-K2.7-Code/raw/main/README.md
- MCP Atlas leaderboard: https://labs.scale.com/leaderboard/mcp_atlas
- MCPMark: https://mcpmark.ai/
- can1357, oh-my-pi GitHub repository (accessed June 15, 2026): https://github.com/can1357/oh-my-pi
Vendor and project-reported metrics are treated as directional, not independent benchmark results.