Any kind of failure can negatively impact a business value and when designing an application we need to proactively design for events like that. The preparation of recovering from a failure is Disaster Recovery(DR). In this blog, we're going to list down the disaster recovery recommendations provided by AWS. We're going to keep the subject brief and will include diagrams as a picture is worth a thousand words.
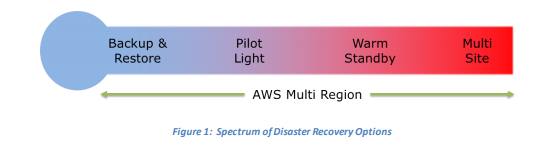
Backup and Restore
This is the traditional method where data is sent for backup regularly. This method takes a long time to restore as we would need to spin up the required components. S3 is typically used to store data or storing snapshots of EBS, RDS and Redshift. Also, we can restore the cached volumes to EC2 or to another site.
Preparation Phase:
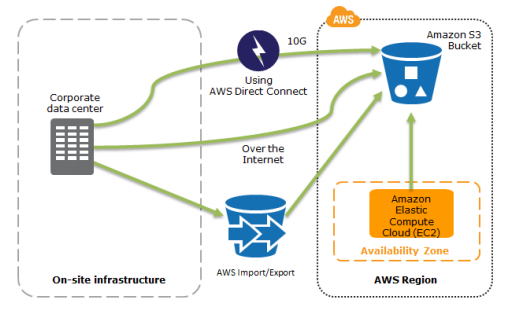
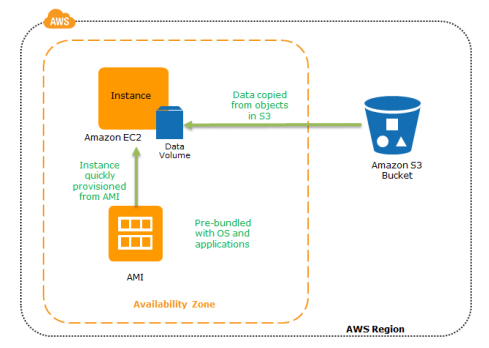
Recovery Phase:
Pilot Light for Quick Recovery into AWS
Pilot light is a DR scenario where a minimal version of environment is always running. We can configure pilot light by running critical components in AWS. This method is faster than Backup and Restore method as core components are already running and are up to date.
Preparation Phase:
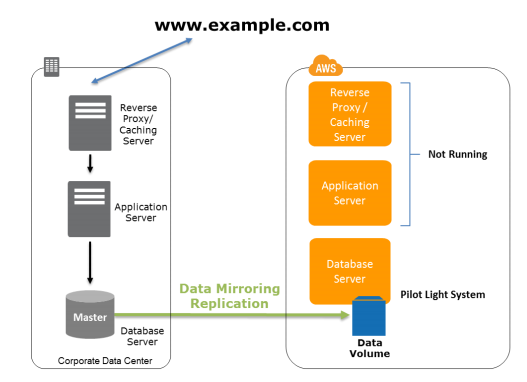
Recovery Phase:
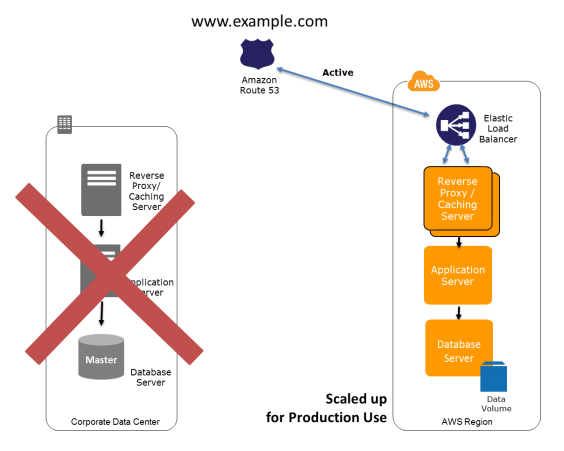
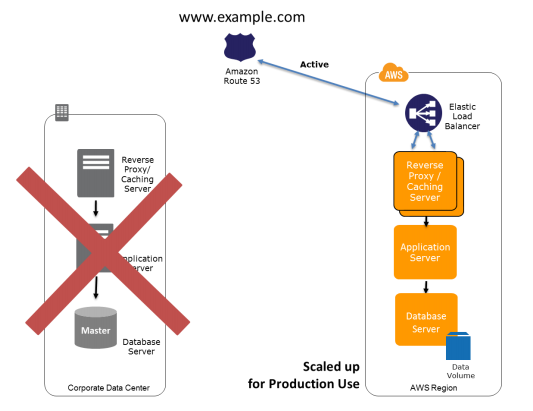
Warm Standy Solution in AWS
In this DR scenario we keep a scaled-down version of the fully functional environment always running in the cloud. It provides a faster recovery than the Pilot light method as some services are always running. All we would need to do is scale up the components.
Preparation Phase:
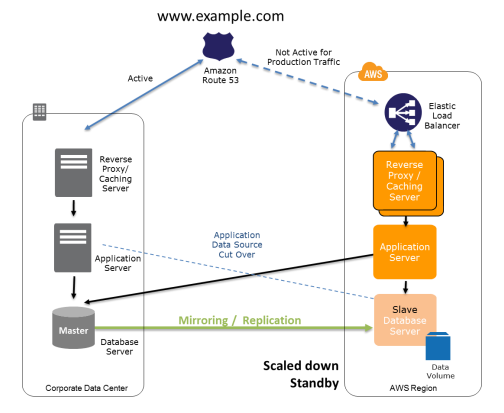
Recovery Phase:
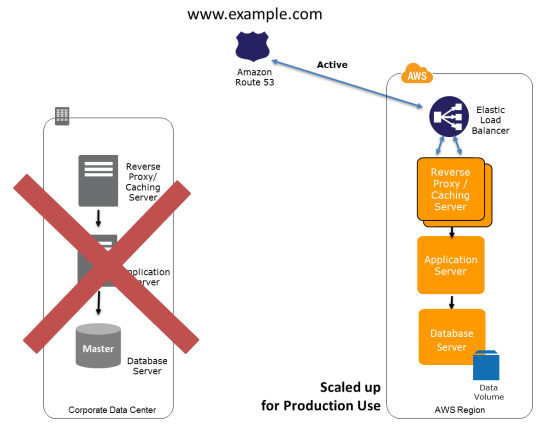
Multi-Site Solution Deployed on AWS and On-Site
In this method we route the production traffic to different sites that deliver the same application of service. A proportion of traffic will go to AWS and remainder to the on-site infrastructure. We can use weighted routing to distribute the traffic.
Preparation Phase:
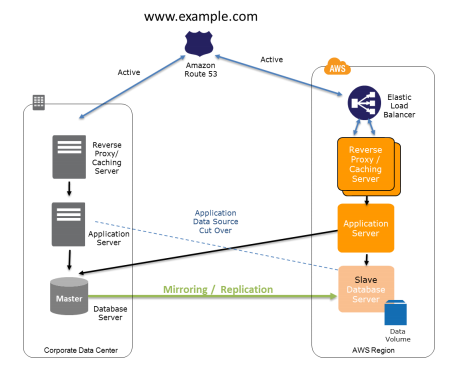
Recovery Phase:
AWS Production to an AWS DR Solution Using Multiple AWS Regions
Each region has multiple isolated locations known as Availability Zones(AZ). We can deploy applications on multiple AZ. Basically make an application multi-site. This way if the application fails on one availability zone, it'll be still up in different AZs and we can route traffic accordingly.
Reference: AWS Disaster Recovery Whitepaper