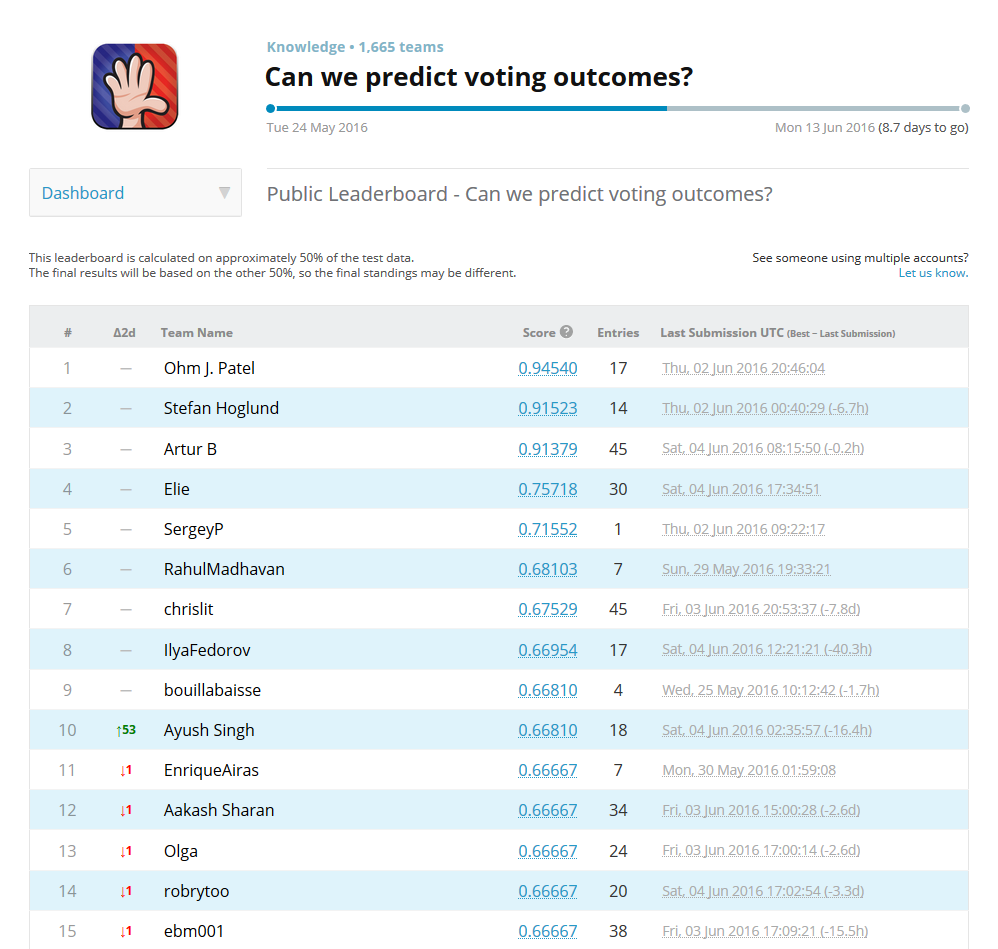
It's an absolute thrill to be in the top 1% of the Kaggle competition hosted by MIT! This contest is no joke, with some seriously experienced ML implementers throwing their hats into the ring. And let me tell you, the top 3 are on a whole other level - they've achieved over 90% accuracy, which is mind-blowing given how noisy the data is.
So, what's the competition about, you ask? We're trying to predict voting outcomes using a dataset from 'Show of Hands' that consists of 108 variables and approximately 5,500 observations. The data is, well, a hot mess, to say the least. There are heaps of missing values – on average, we're talking about 1,900 empty observations for each of the 100 "Question" variables.
I've poured 40+ hours of blood, sweat, and (mostly) brainpower into this competition and picked up loads of new knowledge along the way. From my perspective, it seems that data cleaning takes the cake in importance over modeling for this specific dataset. I was riding high in 7th place, but then life happened and I slid down to 12th. With 9 days left, I'm excited to see how the standings shake out, as I suspect some folks have overfitted their models. Stay tuned for updates on the final results!