Hey there! As your friendly language model, I'm here to help proofread and rewrite your text! Here's the corrected and rewritten version of your post:
Let's do some Machine Learning with SparkR 1.6! The package only gives us the option to do linear or logistic regression, so for this exercise, we're going to train a logistic regression model. I refactored one of my previous projects, which was written in R, to make it work with SparkR. You can find the script here. Unfortunately, there seems to be a bug when we try to train a regression model with more than 8 predictors. So I had to do some feature engineering to select the 8 most important predictors. The dataset has been taken from the UCI ML Repository. Let's have some fun!
In RStudio, run the following code to check the system environment variables for Spark home:
Sys.getenv()
If you don't see SPARK_HOME set or the path is incorrect, don't worry! You can change it via the environment variables. Once everything is working fine, run the following code to load the SparkR library and pass the necessary drivers:
library(SparkR, lib.loc = c(file.path(Sys.getenv("SPARK_HOME"), "R", "lib")))
sc <- sparkR.init(master = "local[*]",
sparkEnvir = list(spark.driver.memory="2g",
sparkPackages="com.databricks:spark-csv_2.11:1.0.3"))
sqlContext <- sparkRSQL.init(sc)Now, let's read the data frame in R and output its contents:
df_r <- read.csv("census.csv")
str(df_r)
Next, let's convert the R data frame to a SparkR DataFrame and print the schema:
census <- createDataFrame(sqlContext, df_r)
nrow(census)
showDF(census)
printSchema(census)
Now, let's randomly split the data so that we can get a better regression model:
trainingData <- sample(census, FALSE, 0.6)
testData <- except(census, trainingData)Once we have the training and test data, let's train our model using Logistic Regression and make predictions:
regModel <- glm(over50k ~ age + workclass + education + maritalstatus + occupation +
race + sex + hoursperweek, data = trainingData, family = "binomial")
summary(regModel)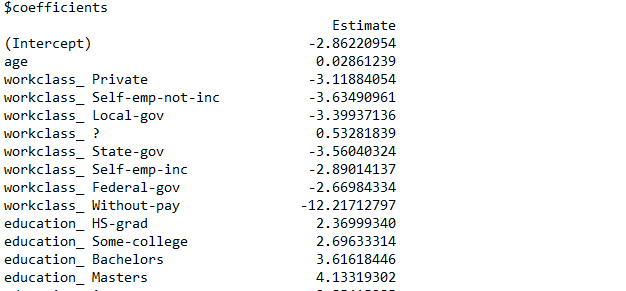
predictionsRegModel <- predict(regModel, newData = testData)
showDF(select(predictionsRegModel, "label", "prediction"))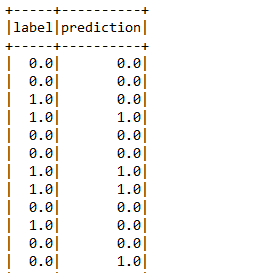
Finally, lets calculate error for each label.
errorsLogR <- select(predictionsRegModel, predictionsRegModel$label,
predictionsRegModel$prediction, alias(abs(predictionsRegModel$label -
predictionsRegModel$prediction), "error"))
showDF(errorsLogR)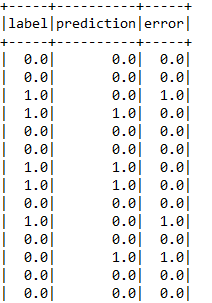
The full script can be found here
After working with SparkR API, I have come to understand that SparkR 1.6 is still in an early phase and have some bugs and limitations. It would be better to use SparkML package as it is more stable, provides more ML algorithms and uses DataFrames for constructing ML pipelines.